
Serverless

AWS Step Functions Pitfalls: 3 Real Problems (and When to Avoid Them)
Last week I got a call asking for help with a nasty bug in production.
The bug dealt with processing data at a scale the dev team hadn’t anticipated. They were using Step Functions to orchestrate a workflow that took an array of objects, processed them, and shoved the transformed objects into DynamoDB.
On the surface, it sounds like a pretty standard workflow - literally what Step Functions was designed to do. But upon closer inspection, we realized we were running into the max request size limit of 256KB because the array was so large.
Debugging the issue took significantly longer than expected because we continuously had to trigger a workflow and wait for it to finish. It was taking 15+ minutes every run because of the amount of items being processed.
I worked with the dev team a bit to figure out alternatives and we eventually landed on a workaround to break up the array into smaller batches and run multiple executions of the state machine started via a Lambda function.
But I don’t really like that solution. Limits are there for a reason. It felt dirty to me how we worked around the problem. So naturally, I took to Twitter to see what you all are doing.
I'm curious to know how/if people process large arrays (~5000 items) with #stepfunctions. That 256kb execution size limit makes it a non-trivial operation.
— Allen Helton (@AllenHeltonDev) May 5, 2022
I received several solid answers and it got me thinking “what are Step Functions not good at?”
Honestly, it’s a short list. But the pitfalls do apply to a range of use cases. So let’s dive in and talk about when it’s better to seek out alternatives like Lambda functions over Step Functions.
Before we start, I want to add a disclaimer - if you look hard enough, you will almost always find a workaround. With Step Functions, workarounds to the problems below are actually viable solutions.
However, the viability will vary based on your comfort level with the service. Some advanced patterns can work around pitfalls, but they might be too difficult to maintain in some instances.
Each scenario below is marked with beginner, intermediate, and advanced skill levels. For the purpose of this article, these skills levels are defined as:
- Beginner - You are just getting started with Step Functions. You have serverless experience but are wondering what all the hubbub is about.
- Intermediate - You understand how state machines are structured and are familiar with production-ready best practices. You know how to use things like Map and Parallel states effectively and are able to keep control of the state machine execution state size and shape.
- Advanced - You are well-versed in event-driven architectures and know how and when to use express vs standard workflows. You know of and use advanced features like waiting for task tokens and executing sub-workflows. You always use direct SDK integrations whenever possible.
With this in mind, let’s talk about some non-trivial scenarios with Step Functions and what you should do based on your comfort level.
You Have Large Payloads
Problem
Step Functions has a max request size limit of 256KB. That means all data you load in your state machine and pass across transitions must be smaller than 256KB at all times. If you load too much data along the way, you will get an exception and the execution will abort.
Beginner
This is a problem that generally sneaks up on you and is a beast to track down. Everything works great until it doesn’t. The easiest thing you can do to manage the execution size limit is trim the state to include only what is absolutely necessary.
Use the data flow simulator to help reshape your data to include as little as possible. This involves making heavy use of the ResultSelector, ResultPath, and OutputPath properties on states.
The issue with this approach is that it doesn’t solve the problem if you can’t shrink your data set down. If you’re comfort level is low with Step Functions, then Lambda functions might be a more appropriate solution.
Intermediate
The official recommendation from AWS is to save the data in S3 and pass the object arn between states. This means when you have a payload that can possibly go over the 256KB limit, you must first save it to S3. When executing your state machine, you pass in the object key and bucket so all Lambda functions can load the data.
A major drawback to this approach is that it makes it harder to use the direct sdk integrations. These integrations use data directly out of the execution state, so you will not be able to pass the necessary information to the API calls because it is stored in S3.
It is a simple solution to an interesting problem, but you effectively eliminate a major benefit of Step Functions. Not to mention you have a performance hit since you will be loading the object from S3 whenever you need to access the payload.
Advanced
With payloads that exceed the execution state limit, you have to trigger your workflows via a Lambda function. With this in mind, you might be able to split up your data and workflow into multiple pieces. If you have a set of activities that need to be performed on a subset of your data, you could create a state machine that does only those tasks.
You could then create another state machine that does tasks on a different subset of your data, and so on. This will create small, “domain-driven” state machines that have narrow focus.
Your execution Lambda function would be responsible for parsing the data into the appropriate pieces and executing each state machine with the proper data. After running all the state machines, it would piece the data back together if necessary and return the result.
This approach brings back the ability to use direct SDK integrations, but it does add complexity to your solution. By managing more state machines, you might have difficulty maintaining the solution down the road.
Be careful with this approach, you don’t want the Lambda function to wait for the execution to finish for all the state machines. That would rack up a hefty bill. Instead, you could try using the scatter/gather pattern to trigger a response on completion.
Note - This might be the fastest/most performant solution, but in practice the intermediate approach is the safer bet.
You Process Lots of Data In Parallel
Problem
Step Functions has a maximum number of history events of 25,000. This means if you have a data set with thousands of entries in it, you might exceed the limit of state transitions. You might also run into the data size limit as well for sets that large.
Large data sets that need to be processed concurrently sounds like a great use for Step Functions. However, if you are doing parallel processing via a Map state, the max concurrency limit is 40. Meaning you will be processing the data in “batches” of 40. So your parallel processing might not be as fast as you think.
Beginner
If your workflow is running asynchronously, it might be best to accept the 40 concurrent Map executions and wait for it to finish. There’s nothing wrong with this approach until you get close to the 25,000 event history limit.
When that starts to happen with your state machines, you might need to start doing some math and figuring out what your max item count is. Once you figure out your max item count, then you can run your workflow in parallel batches. Similar to what I did to solve that production bug mentioned earlier.
To address the large data size that comes along with big arrays, you would need to adopt the same approach as listed above, where the payload is saved into an S3 object and loaded, parsed, and split via a Lambda function at the beginning of the state machine.
Intermediate
The solution for an intermediate approach is similar to the beginner, but it involves more automation. If the array you are processing lives in a database like DynamoDB, you can load a subset of the data to process from within the state machine.
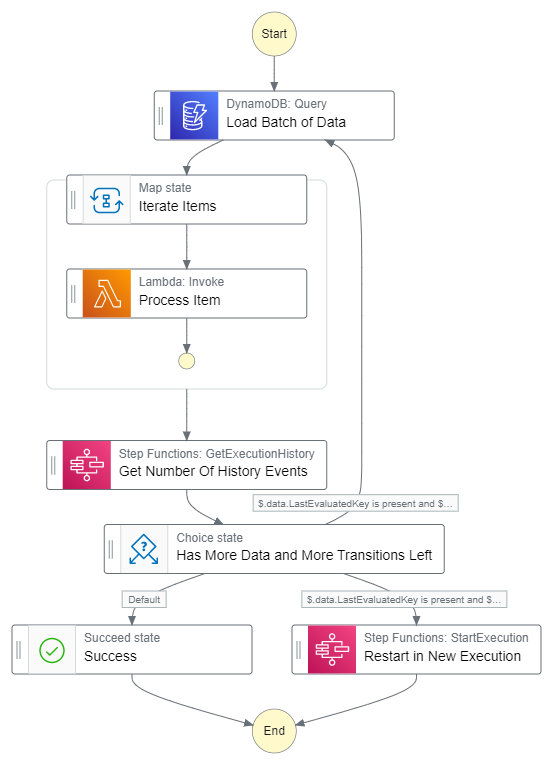
Diagram of a state machine that loads from the database and keeps track of state count
The state machine loads a subset of the data using the limit property. It then iterates over the returned items in a Map state.
Once the items are done processing, it loads the execution history and looks at the Id property of the last item to get the number of events have occurred. If there are still enough events left without getting too close to the 25,000 limit, it starts from the beginning. If it is getting close to the limit, the state machine will start another instance of itself to restart the count and continue processing where it left off.
This process will get you pretty far. But in terms of speed of execution, it could be faster. This approach works in sequential batches of 40. So your large datasets could take a significant amount of time to process.
Advanced
Justin Callison, senior manager of Step Functions, walks us through an advanced approach toward blistering fast parallel processing by structuring state machines as orchestrators and runners.
The orchestrator parses your dataset into batches and passes a single batch to a runner. The runner takes the batch and works the items. If a batch has more than 40 items in, it splits the data into 40 more batches and recursively calls itself to fan out and process more items in parallel. The state machine will continue to split and fan out until there are fewer than 40 items in each batch.
The article goes into great detail and even provides a working example in GitHub.
This method completely addresses the parallel problem, but is the most advanced approach by far. Make sure you are comfortable with Step Functions before going down this route. As with anything recursive, a small bug could send you in an infinite loop and cause a significant bill.
You Cross Service Boundaries
Problem
When building workflows, sometimes you need to manipulate data in multiple microservices. Microservices are a logical separation of AWS resources that may or may not live in the same account. Each microservice should be self contained and only use its own resources, not resources from other services.
Directly using resources from other microservices would create tight coupling, which is an anti-pattern in serverless and microservice design. Step Functions makes it easy it cross these service boundaries if you have multiple microservices deployed into the same AWS account. It’s up to you to be vigilant when you’re building your state machines.
Beginner
Caution - what I’m about to suggest is anti-pattern and I do not recommend it for production use!
When starting out with Step Functions, it is entirely possible to use Lambda functions, SQS queues, SNS topics, etc… without regard to which microservice they belong to. The workflow studio lets you simply select a Lambda function from a drop down. There are no restrictions for which functions you can use because microservices are a logical construct.
If you’re using Infrastructure as Code (IaC) it’s a matter of exporting the arn of a resource and importing it into the template of another service. A little more difficult, but still relatively easy.
Nothing stops you from going across microservice, and it would get the job done. So while it’s not recommended, it is often the easiest approach to solving cross-service boundaries.
Intermediate
While invoking resources directly might be an anti-pattern, calling a cross-service API is not. If you have your resources behind an internal API, it is absolutely acceptable to call it. Calling an API provides loose coupling, which is much more acceptable in serverless and microservice environments.
Since Step Functions do not currently support calling external APIs natively, you have two options for incorporating this approach into your workflows.
- Create a Lambda function that calls the API over https
- Setup an HTTP integration in API Gateway to forward the call to the API
The Lambda function can be as simple or complex as you need it to be. If you want to transform the response before you return it to the state machine, do it. If you want to do a straight pass through, that is an option as well. The objective with this approach is to call an API using something like axios or requests.
The HTTP integration is essentially creating a proxy from an API Gateway in your microservice to call an external endpoint. When going this route, you can call the API Gateway invoke SDK integration to make the call directly. This provides a higher performing solution than the Lambda function.
Advanced
If the cross-service call you need to make is a long-running or multi-step process, you don’t want a synchronous solution like what was listed above. Instead, you need to pause execution and wait for a response in order to resume. Sheen Brisals shows us how to use EventBridge to do just that.
The EventBridge integration will fire an event, pause the state machine execution, wait for an event to be processed in another service, then resume the workflow when the other service fires an event back. This is known as the callback pattern.
The callback pattern is another way to provide loose coupling between your microservices. It does add a layer of complexity to your solution, but provides the most flexibility and highest reliability. Just be sure you configure the state machine heartbeat to abort execution if something goes wrong in the other microservice.
Conclusion
There are a few situations where Step Functions might not be the best AWS service to use when it comes to creating workflows. How you handle large payloads, high volume arrays, or cross service boundaries varies based on your level of comfort.
If you pursue an option outside of comfort level, remember that the right solution isn’t the one that works, it’s the one that works and you’re able to effectively maintain. This means if there’s a defect, you have to know how to troubleshoot a problem and dive through traces.
Sometimes it’s better to just go with Lambda.
It’s not a bad thing to go with the simpler option based on the skills of your engineering team. Something we are all constantly working on is upskilling. Improving our comfort level with new cloud features or new architectural patterns or entirely new services is part of working in the cloud. We love it.
Step Functions is an amazing alternative to Lambda functions in a multitude of use cases. They offer high traceability in asynchronous workflows and in some instances are cheaper to run than Lambda functions. There are even ways to eliminate the infamous serverless cold start by integrating API Gateway directly to an express state machine.
Step Functions are turning out to be the swiss army knife of the serverless world. It enables consumers to do many things quickly and easily. It’s just not always the most beginner friendly.
I highly encourage you to try out Step Functions if you haven’t already. The pros greatly outweigh the cons and they offer a high degree of visibility into your server side operations. You can visit my GitHub page for a variety of examples.
Happy coding!


{kind=link}
Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.