Software engineering is one of those industries that likes to periodically humble you. You think you know exactly how to build something, come up with a plan and an estimate, sit down to start writing some code, and BOOM. It does not at all work like you thought it did.
That happened to me the other day.
I was building a basic multiplayer puzzle game that required all the players to start playing at the same time. The game took roughly 20 seconds to play, so I figured I’d send out a broadcast push notification every 30 seconds to start the next round. I’ve used the EventBridge Scheduler a bunch of times over the past year, this sounded like an easy task. I just needed to create a recurring schedule every 30 seconds that triggers a Lambda function to randomize some data and send the broadcast.
It wasn’t that easy. The smallest interval you can set on a recurring job via the scheduler, or any cron trigger in AWS for that matter, is 1 minute.
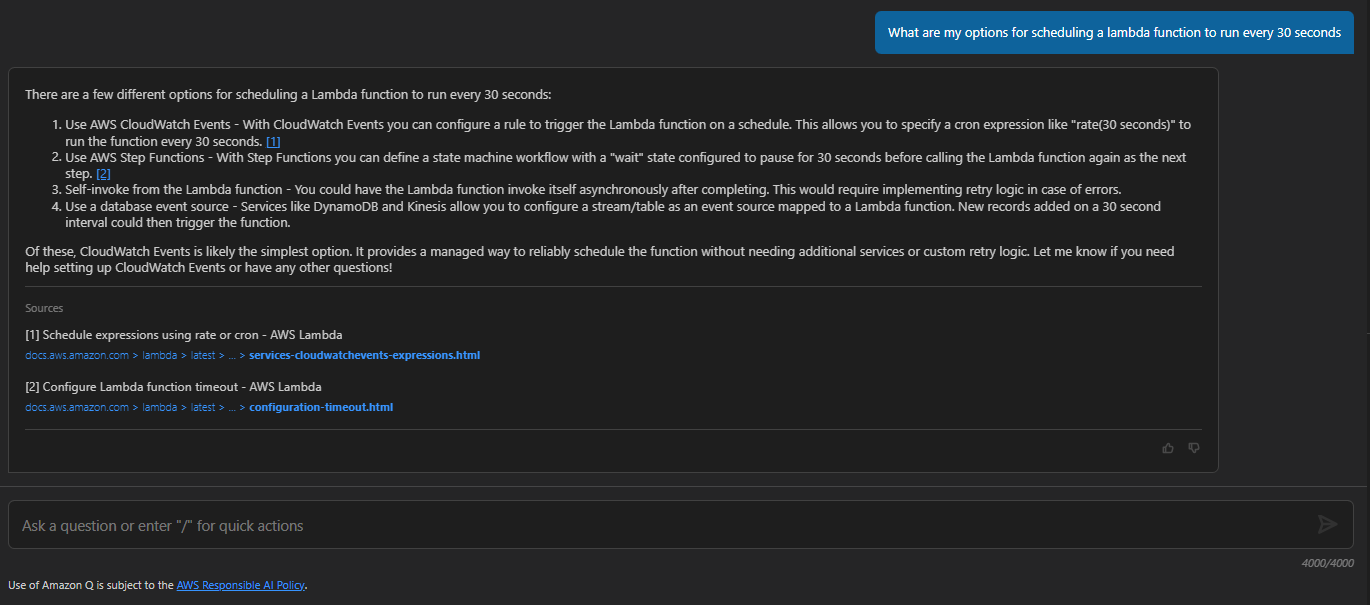
I asked Amazon Q what my options were and had mixed feelings about what it said.
As I just mentioned, the first option Q gave me is wrong. If you put in a value of rate(30 seconds) into a schedule, you get an error saying the smallest rate it can do is 1 minute. So that option was out. Option 2 with Step Functions was intriguing and we’ll talk more about that one in a second.
Option 3 where you recursively call a Lambda function seems like a terrible idea. Not only would you need to pay for the 30-second sleep time in the execution, but this method is also imprecise. You have your variable time of compute for the logic, then a sleep time to bring you up to 30 seconds. What’s more, this puts you in a loop, which AWS detects and shuts down automatically. You can request to turn it off, but the docs make me feel like you really shouldn’t.
The last option given to us by Q was triggering the Lambda function off a database stream - which in itself sounds like a reasonable idea, except you’d have to have a mechanism that writes to the database every 30 seconds, which is what we’re trying to do in the first place. So that doesn’t solve our problem at all. This leaves us with Step Functions as our only real option according to Amazon Q. Let’s take a look at that.
Before we continue, if you’re here looking for the code you can jump straight to GitHub and grab it there.
Using Step Functions for 30-second timers
Step Functions itself doesn’t allow you to trigger things at sub-minute intervals. It is still constrained to the 1 minute minimum timer. However, what Step Functions has that other things do not is the wait state. You can tell Step functions to run your Lambda function, wait for 30 seconds, then run the Lambda function again.
This is what I did in my first iteration and received a wealth of mixed opinions on Twitter 😬
I needed to run a Lambda function every 30 seconds but the lowest granularity you can set EventBridge schedules or cron tasks to is 1 minute.
So I'm now triggering a Step Function workflow every minute, running my function, sleeping for 30 seconds, and running my function again pic.twitter.com/KeqV2mUxlO
The premise was simple. I would trigger this state machine to run every minute. It would immediately execute my Lambda function that did the broadcast, wait 30 seconds, then run the Lambda function again. Easy enough, right?
After being told time and time again that this solution seemed really expensive, I wanted to see how much it cost to run for a month. I was using standard Step Function workflows, which are billed by number of state transitions as opposed to execution time and memory, which is how Lambda and express workflows are billed.
Standard workflows cost $0.000025 per state transition. As far as costs go in AWS serverless services, this one is generally viewed as expensive. I don’t disagree, especially if you make heavy use of Step Functions on a monthly basis. But what you’re paying for here is much more than state transitions, you’re also paying for top-of-the-line visibility into your orchestrated workflows and significantly easier troubleshooting. It’s an easy trade-off for me.
My workflow above has three states, but five state transitions! We are always charged a transition from “start” to our first state and from our last state to “end”. If we run our workflow every 30 seconds for 24 hours, we can calculate the math like this:
5 transitions x 60 minutes x 24 hours x 2 iterations per minute x $.000025 = $0.18
Ok $0.18 per day isn’t that bad. That’s $65 per year for the ability to run something every 30 seconds. But I’m confident we can do better.
Minimizing state transitions
We know that state transitions literally equal cost with Step Function standard workflows. We also know that every time you start a workflow you’re charged 2 transitions for start and end states. So what if we just added more wait states and function calls?
I started down this path and very quickly realized it was not a good idea. It’s probably not very hard to see why based on the picture below.
This workflow is a nightmare to maintain. It’s the same function being repeated over and over again with the same wait state between each execution. If I wanted to extend it with more executions, I’d add more states. If I ever changed the name of the function, then I’m in for a lot of unnecessary work updating that definition in X number of spots.
However, this did cut down on the number of state transitions. Instead of triggering the workflow every 60 seconds, I could now trigger it every 2 minutes, eliminating half of the start/end transitions every day. I liked that.
Doing the math, it ended up saving $.02 per day. What I needed was to queue up something like that over the course of an hour, but I wasn’t about to maintain a workflow that used the same function + wait combo 120 times in it. So I made it dynamic.
Dynamic loops
My goal here was to minimize the number of times I ran the workflow each day so I could keep the number of state transitions to a minimum.
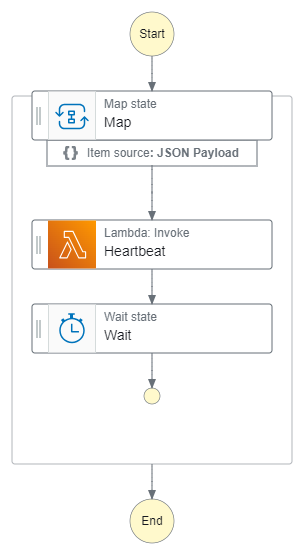
Turns out I can use a Map state to loop over the function execution and wait states. Maps do not charge you a state transition when it goes back to the start. This is perfect! Exactly what we needed to reduce the number of start/end transitions. It also is a much, much simpler workflow to maintain.
But there are a few things we need to keep in mind.
Maps aren’t “for loops”
As much as I’d like to say “run this loop 100 times,” in a Map state, it doesn’t work that way. These states iterate over an array of values, passing the current iteration value into the execution. Think of it like a foreach rather than a for. To get around this, we need to pass in a dummy array with N number of values in it, with N being the number of executions we want to run. For our workflow above, that means an initial input state like this:
{
"iterations": [1,2,3,4,5,6,7,8,9,10]
}
This would result in 10 executions of the Map state. We can include as many iterations as we want here to reduce costs with one exception. More on that in a minute.
Threading
Map states are concurrent execution blocks. The Step Functions team recommends going up to 40 concurrent executions in your Map states for normal workflows. But we don’t want multi-threaded execution in this workflow. We want the iterations to go one after another to give us that every 30 second behavior.
To do this, we must set the MaxConcurrency property to 1 so it behaves synchronously. Without this, our state machine would be starting games all over the place!
Execution event history service quota
Did you know there is a service quota for a state machine execution that limits the number of history events it can have? Me neither until I ran into it the first time.
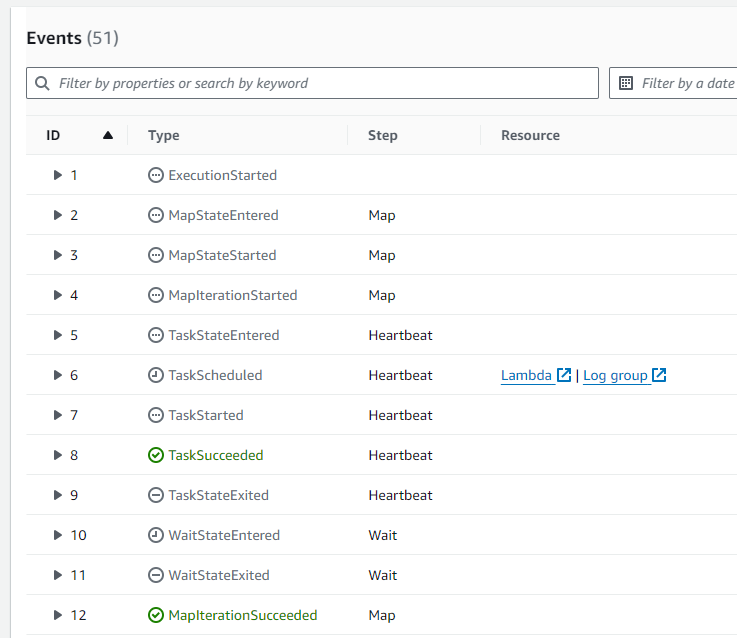
You can have up to 25,000 entries in the execution event history for a single state machine execution. Before you ask, no that does not mean state transitions. These are actions the Step Function service is taking while executing your workflow. Take a look at the entries for our state machine.
You can see that each Map iteration adds 3 entries to the execution history. On top of that, each Lambda function execution adds 5 entries, and the wait state adds 2. So each Map iteration for our specific workflow adds 10 entries. There are also entries for starting and stopping the execution and the Map state itself. To figure out the maximum number of loops we can pass into our map, we need to take all of these things into consideration.
(25,000 max entries - 5 start/stop entries) / 10 loop entries per iteration = 2499 iterations
So we can safely loop 2499 times without exceeding the service quota. At 30 seconds an iteration, that will get us through a little over 20.5 hours. To give it a little buffer and to make nice, round numbers we can safely run this state machine for 12 hours. This would result in a starting payload like this:
{
"iterations": [1,2,3,4,5...1440]
}
This will result in our Map state looping 1440 times over the course of 12 hours, putting us well within our execution event history service quota and reducing the number of start/stop state transitions by 2872 every day or roughly $.07, which is a 39% cost reduction!
Deployment and configuration
Now that we understand conceptually how this works, it would be nice to look at an example so we can understand the moving parts. If we want our state machine to run every twelve hours, we can add a ScheduleV2 trigger in our IaC along with the iterations array we defined earlier.
In the real implementation, you would include all the numbers in the array and not use 5…1440 like I did. I did it that way for brevity. Nobody wants to read an array with 1440 items in it 😂
This type of trigger in SAM sets up an EventBridge Schedule with the rate you configure and passes in whatever stringified JSON you have for input to the execution. Depending on your use case, you can change the rate and iteration count to whatever you want - as long as it doesn’t surpass the execution event history quota.
There is no magic with the state machine itself. It is looping over the function execution and wait state as many times as we tell it to.
Advanced usage of this pattern
This is a great pattern with straightforward implementation if you want to build something like a heartbeat that runs at a consistent interval around the clock. But what if you don’t want it to run all the time?
The use case I had for my game fit this description. I wanted it to trigger every 30 seconds between 8 am and 6 pm every day, not 24/7. So I needed to come up with a way to turn the trigger on/off on a regular interval. This made the problem feel much harder.
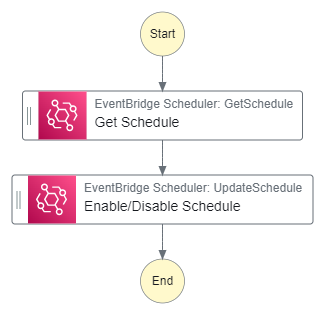
To get the behavior we want, we need to turn on and off the recurring EventBridge schedule for our state machine at specific times. So I built another Step Function workflow that simply toggles the state of the schedule given an input.
This state machine is triggered by two EventBridge schedules:
Every day at 8 am that enables the 30-second timer state machine schedule
Every day at 6 pm that disables the 30-second timer state machine schedule
To change the behavior of each execution, I pass in either ENABLED or DISABLED into the input parameters in the schedule.
By doing this, I also need to change the iterations of my 30-second state machine since it isn’t running 24/7 anymore. Since it’s only running for 10 hours, I can update the interval to rate(5 hours) and update my input intervals from 1440 to 600 and I’m all set!
Final thoughts
There is more than one way to trigger tasks in sub-minute intervals. In fact, there is an entire chapter on the concept in the Serverless Architectures on AWS, Second Edition book by Peter Sbarski, Yan Cui, and Ajay Nair. I highly recommend that book in general, not just for the content on scheduling events.
Everything is a trade-off. You’ll often find scenarios like this where cost and complexity become your trade-off. Figure out a balance to make things maintainable over time. Human time almost always costs more than the bill you receive at the end of the month. Time spent troubleshooting and debugging things that are overly complex results in lost opportunity costs, meaning you aren’t innovating when you should be.
The solution I outlined above balances cost and “workarounds”. I had to use a workaround to get the Step Functions Map state to behave like a for loop. I had to work around not being able to schedule tasks more frequently than 1 minute. I worked around scheduling tasks over different parts of the day. All of these things add up to make for an unintuitive design if you’re looking at if for the first time. Somebody will look at all the components that went into it and say “this is just to trigger an event every 30 seconds? It’s way too much!”
In the end, it worked out for me and my use case. I was able to save some money while getting the features I was looking for.
Do you have another way to do this? What have you found that works for you? Let me know on Twitter or LinkedIn, I’d love to hear about it!
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: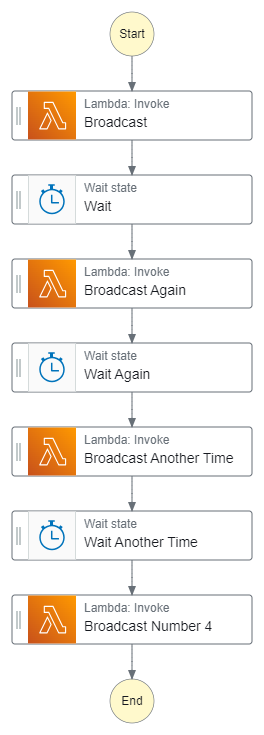


{kind=link}