Have you ever heard the saying “it takes a village to raise a child”? Well, what if the village was 6 part-time volunteers and the child was a thriving technical community with over 900 members? For the Believe in Serverless (BIS) community, that’s the reality. Getting its start in January, the BIS community had humble beginnings. A slow-rolling Discord server and a once-a-week livestream with a few community members and the community champions. But the community took off real fast, growing the Discord server by hundreds of members over a few months and diving into 3+ live sessions every week. Between day jobs, moderation, event-planning, promo material creation, and social media marketing, the community had quickly run into unsustainable growth. There was no way the 6 of us (Ben Pyle, Danielle Heberling, Andres Moreno, James Eastham, Khawaja Shams, and me) could dedicate the time needed to establish processes and run things consistently.
Add the session to the Believe in Serverless website
Set reminders to post about the session in Discord, LinkedIn, and Twitter
I had written up a Google doc that detailed all the tasks step by step. It was somewhere around 21 steps end to end. Way too much for a volunteer activity that we were doing three times a week. We also found ourselves scrambling on the day of the sessions asking each other, “Did you promote this session on Twitter?” To which the answer was usually “Oops, no I forgot 😬”
Luckily, pretty much everything in the process has APIs - which meant I could automate a majority of it. Let’s take a look at what I built. It had lots of new things in it (for me) plus some enhancements to existing projects I’ve built in the past.
The big picture
If you want to jump straight to the code, you can find it in GitHub. The infrastructure is written in a SAM template and can be deployed to your AWS account using the sam deploy --guided command.
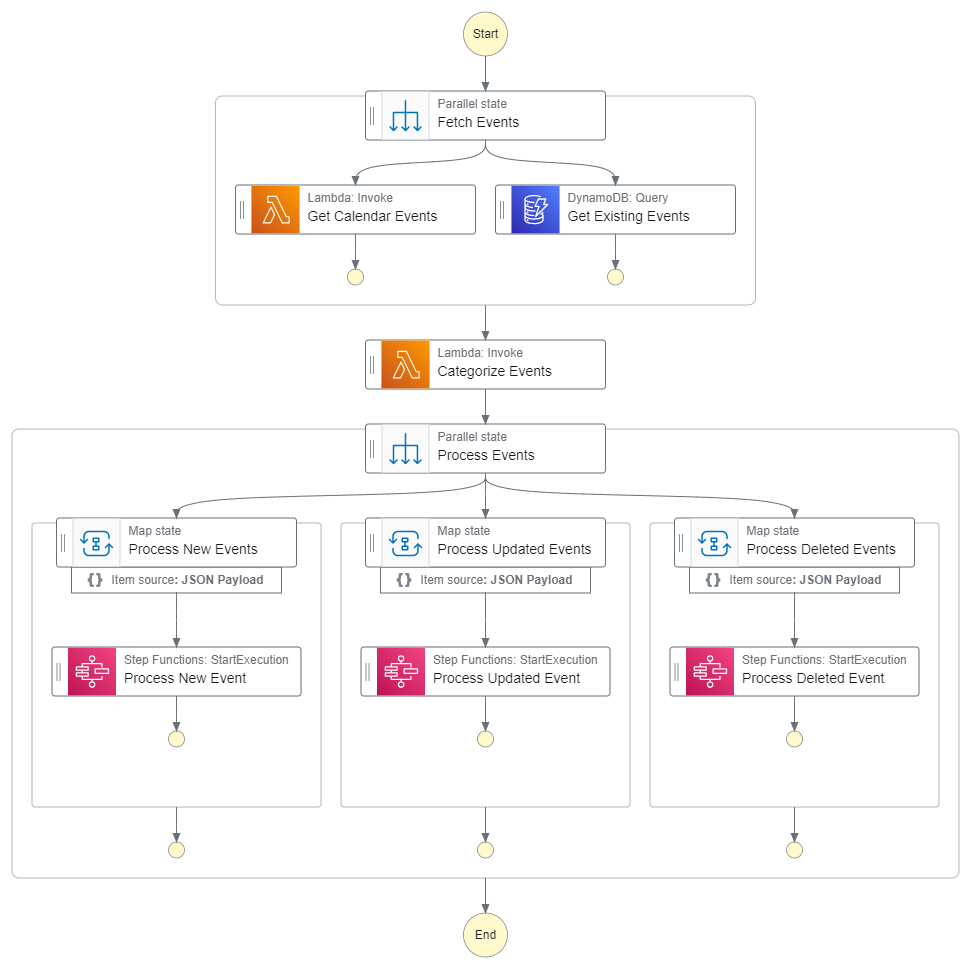
As with most of the automations I build, they are multi-step processes that perform enrichments, transformations, and communicate with 3rd party APIs. With this in mind, I opted for AWS Step Functions to coordinate the pieces of my workflow. For this build, I use two separate state machines - a driver and a processor.
The driver
The driver state machine is responsible for categorizing events from the Google Calendar and running the processor with the correct context. It loads all future events from the Google calendar and compares them to the events it has processed before. It runs a quick comparison to see which events are new, deleted, or had the date changed.
Once categorized, the workflow splits into three branches, iterating over each of the new/deleted/updated events and kicking off the processor state machine with the operation it needs to perform.
This state machine runs at 10pm every day. It gives me or the other community champions time throughout the day to make updates to the calendar, then it processes them while we’re offline. It’s kicked off by an “old school” cron trigger, which is nothing more than an EventBridge rule set to execute on a recurring schedule.
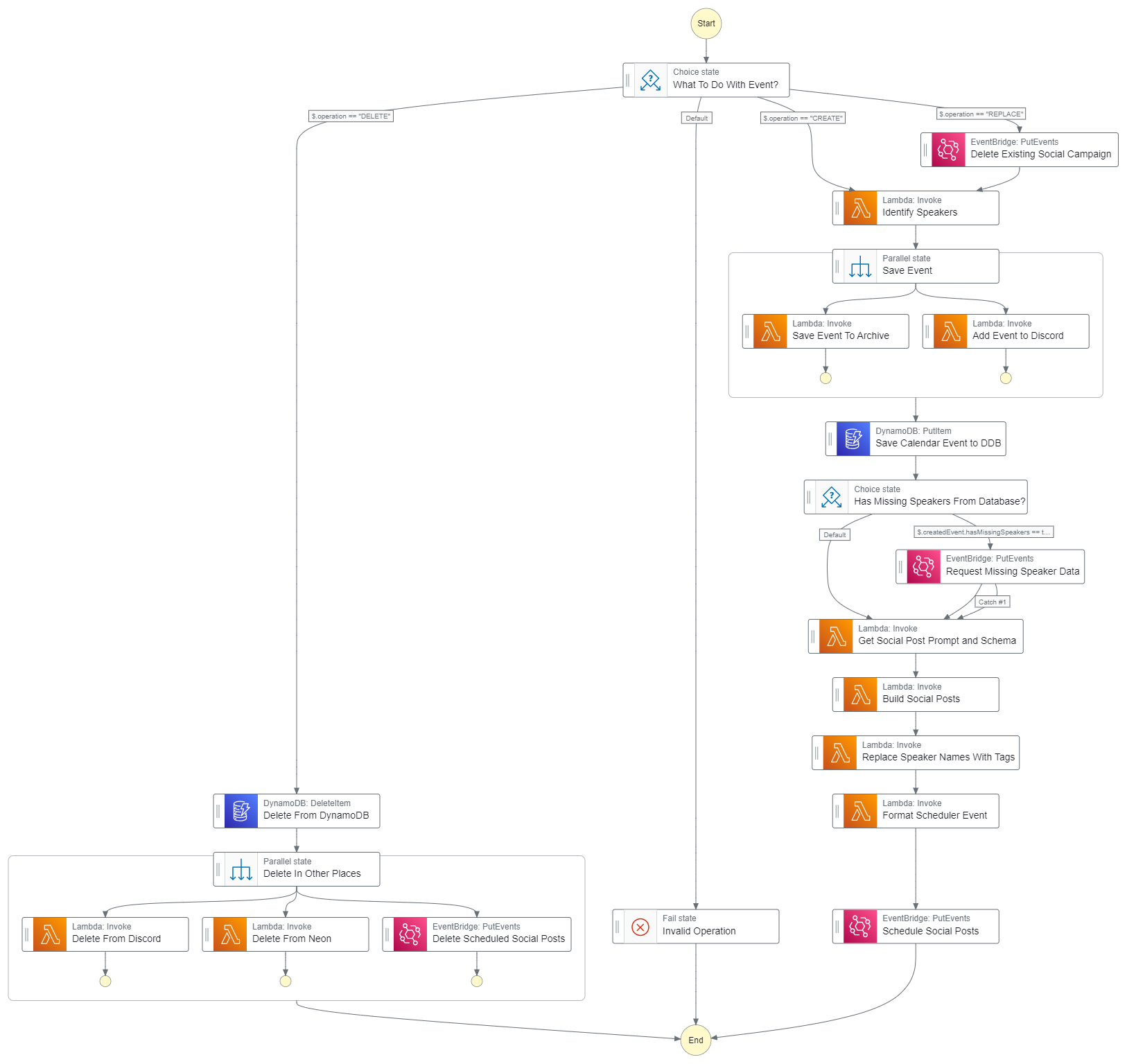
The processor
This state machine is where the real work gets done. Consider it the true “automation” workflow. Calendar events that are sent to this state machine are told to either CREATE, REPLACE, or DELETE the event from the system. Below you can see the entire state machine and the steps it processes for each operation.
Based on the operation, a different branch is taken in the workflow. This easily could have been split into different state machines, but my personal preference is to see the whole thing to allow for easier debugging. In this post we’ll cover the big part of the workflow - creating an event.
Creating an event
The input of this state machine is a transformed version of the Google calendar event. Let’s take an example from a recent livestream.
{
"operation": "CREATE",
"event": {
"id": "62ensjimucn62kbs2vqs5p3aof",
"contact": "allenheltondev@gmail.com",
"title": "Can you build an entire app with Anthropic artifacts?",
"streamLink": "https://www.youtube.com/watch?v=YcSZhfa82TI",
"registrationLink": "https://www.google.com/calendar/event?eid=NjJlbnNqaW11Y242Mmtic",
"description": "Join Allen Helton and Andres Moreno as they jump into the deep end with Anthrophic's artifacts...",
"startDate": "2024-08-29T16:00:00.000Z",
"endDate": "2024-08-29T17:00:00.000Z",
"image": "https://drive.google.com/uc?export=view&id=1Ao5O0V9U82lE79AegjxrhoM928kRm1QH"
}
}
Some of the information above is truncated for readability, but you get the gist. The information in this JSON object is enough for us to do the plethora of administrative tasks required to effectively advertise, promote, and run a livestream while going hands-free.
The first thing we do is create a duplicate of this event in Discord. We do this to bring visibility of the session to the heavy Discord users. Discord has an events tab that shows upcoming events integrated within the application. When the event is live, the tab turns into a “Join now” button that takes you straight to the event, wherever it’s hosted (in our case, it’s hosted on YouTube). This provides a seamless experience for some users who are in it every day and don’t like that “swivel chair” experience of using multiple apps.
To create the event in Discord, we use a Lambda function that calls the Discord API using information from the input we recieved from Google calendar. The title, streamLink, description, startDate, endDate, and image are all used to set it up and point people in the right direction. The id of the event is saved so we can associate the Discord event to the Google calendar event in case something changes.
We also save the same metadata about the event in Neon, a serverless Postgres service, for data archival because once the Discord event happens, it’s deleted and the record is gone forever. Since I’m a data hoarder, I like being able to look back and see what our sessions were, what they were about, and who gave them.
Speaking of who gave sessions, let’s talk about that for a minute because that’s probably my favorite part.
Speakers
My first iteration of this project was simple. I just wanted the names of the people giving the sessions so I could add them in Postgres and do a query to see all the talks they’ve given for the Believe in Serverless community. With a relational database, this is easily done with a link table and a simple query:
SELECT e.title, e.startDate
FROM EVENT e
INNER JOIN SPEAKER_EVENT se ON e.id = se.eventId
INNER JOIN SPEAKER S ON S.id = se.speakerId
WHERE s.name = 'Allen Helton'
This on its own is extremely useful. But keep in mind, my goal of this entire project was to minimize the amount of work the community managers were doing when creating events. I didn’t want them to add more data in some hidden field that explicitly listed the speaker so my automation could pick it up and shove it in a database. I wanted this information with zero extra lift. So I used the world’s greatest regular expression: Claude 3.0 Haiku.
The description of the event always has the name of the speakers. Using a real regex was off the table because how on earth would that work? So I used a powerful, fast, and simple LLM to identify speakers by providing the description of the event. Here’s the prompt I came up with to find speaker names.
Identify the speakers in this description for an event. Return your answer as a comma separated list in a <speakers> tag. <description>{eventDescription}</description>
Simple enough! When I get a response, it’s in xml format like this: <speakers>Allen Helton, Andres Moreno</speakers>. So a quick parse, a string split on the comma, and boom! Speakers. By using Claude Haiku, I’m taking advantage of a faster model while keeping costs down to a minimum. It’s the “least capable” model in the Claude line, but more than enough to identify a person’s name in a blob of text.
My least favorite thing about this process is handling xml. That wasn’t my idea, it’s actually recommended by Anthropic. But hey, if it gets the job done reliably, I’ll take a step back into the early 2000’s for a minute 😉
Social media posts
Reminding people that an event is coming up while trying to get them excited for it but not annoyed that you keep bringing it up (that was a mouthful) is a tricky balance. You obviously don’t want people to forget the session is happening and to set aside time to see it, but you also don’t want to nag them over and over - especially if they’ve already said yes.
So I’m conducting an experiment. Not only am I trying to find the right balance of messages to send for each event, but I’m also trying to find the best times to send them. Right now the current thought is to send them:
5 days before
3 days before
1 day before
30 minutes before
Immediately when the session starts
These are all sent approximately at start time of the session, but you know, 5, 3, and 1 day before the event. That way if we have a speaker giving a talk for EMEA, we aren’t advertising it heavily to Americans when they are asleep.
So that’s 5 times to post on social media. The automation I built will post the reminders on X and Discord (soon LinkedIn as well, but that’s been a frustrating effort and a story for another day). But it’s not that simple. When you go to X, you have certain expectations about the content you see. Same with Discord. So the social media posts need to be worded a little differently based on the platform they will be posted on. Which means we’re actually posting about a session 10 times!
I don’t know about you, but I don’t want to come up with 10 social media posts for every session. The community rocks anywhere from 2 to 6 sessions weekly. That would create way too much work for the community managers. So it was back to the LLMs, but not Claude this time. I’ve found OpenAI to be significantly more capable when it comes to social media messages. The quality is higher, plus I get a guaranteed JSON output that’s easy to pass along in my state machine. The prompt looks like this:
systemContext: You are an expert social media marketer in the tech industry. You create social posts that have high engagement and registration conversions.
prompt: Generate 5 social media posts each for Twitter, LinkedIn, and Discord for an upcoming event. These posts should encourage registration and get people excited about the content. The posts should vary in content and be created for when the event is 5 days away, 3 days away, 1 day away, 30 minutes away, and starting now. It is ${new Date().toISOString()} right now. Extract details from the following event JSON and use it to build engaging posts. Be upbeat, use minimal emojis and zero hashtags, and provide a positive vibe that promotes a sense of community. Build anticipation and encourage followers to attend as the event gets closer. All posts must include a link at the end of the message. The only posts that should include the streamLink is the 30 minutes before post and the start of the event post. All others must include the registrationLink. Instead of saying to register for the event say something like "mark your calendars". Use the speaker's name and do not attempt to tag them. Create the posts with relevant tone for all social platforms. Use the UTC startTime of the event to choose an appropriate sendAtDate for each post. If the event has an image, include it in the post object for the 5, 3, and 1 day out posts. Respond only with JSON. Event: ${JSON.stringify(state.event, null, 2)}
You can tell by the way things are phrased that I went through a few iterations 😁. I ran into some issues with OpenAI trying to tag speakers with made up handles. I have no idea why it did that, but I was able to get around it. Anyway, the result of this prompt is a JSON object that contains arrays of messages for LinkedIn, X, and Discord. Each object in the arrays contains the message and the date and time when the message should be sent.
From there, I simply pass that along to the social media scheduler I built last year for Ready, Set, Cloud, and I’m done. The scheduler will manage campaigns (a series of related messages) for me and post all the messages on the proper platform at the right time without me needing to do anything. It’s a completely hands-free social media marketer. Could the quality be a little bit better? Yes, of course. But you can’t beat zero work!
The outcome
The day this was launched, I breathed a huge sigh of relief. Outside of a couple of minor bugs, the entire process just worked. It reduced the amount of work for the community managers by almost 4x while improving our social media presence. Efforts were consolidated, there became a single source of truth for events (which is underrated), AND we finally had a public facing calendar the community could subscribe to!
I don’t regret letting the process get to the point it did before building the automation. I consider it growing pains. It’s a success indicator. Growing from one session a week to 3-6 is a wonderful problem to have. It honestly reminds me of a blog post I wrote years ago called “just hardcode it” where I talk about doing the minimum amount possible for as long as you can. Nobody wins with a bunch of premature optimization.
Of course, I had also taken this as an opportunity to learn some new things. I returned back to relational data modeling with my Neon database. I also had to learn the nuance of PostgreSQL compared to my years of experience with SQL server (it wasn’t too bad). I also made a serverless Discord bot, which felt a bit against the grain. Discord bots do best in a stateful environment, of which serverless… is not. But I figured that out and have been able to reuse it in other projects I’ll write about in the near future.
Hopefully you’re already a member of the Believe in Serverless community. If not, consider joining and tuning in to our weekly sessions from practitioners all over the world.
I had a great time building this project, as I always do with my automations. And if you know me at all - you know I can’t leave well enough alone. I’ve iterated this design a bit to better attribute the presenters of each session. But that’s a story for another day.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: