How I Built A Santa Chatbot To Mess With My Brother
By Allen Helton16 December 2023
I like to think of myself as a good big brother. I offer guidance and advice to my little bro whenever he needs it and listen when he’s having a rough time. But beyond that, I like to give him a particularly fun Christmas every year. Something he can’t get anywhere else.
My family is all about experiences and making memories. So for Christmas each year, I like to give my brother his presents in peculiar ways that he’ll never forget. A few years ago I drew detailed sketches of different Native American tribe members on each of his gifts. I told him to open his gifts starting with the westernmost tribe and ending with the easternmost tribe. Naturally, he had no idea, so he got a good American history lesson that day 🤣.
I did stuff like this for a few years until I realized I could amp it up with software. I love building in public, learning about new services, and flexing my creativity, so I started having some fun with it. One year I bought a bunch of phone numbers and made him call or text his presents to figure out which one to open first. The year after that I made a dungeon crawler mobile app controlled via Alexa. He had to talk to Alexa to move around the dungeon and find which presents to open next. I pushed updates to the mobile app via a WebSocket for a fun, interactive experience.
This year is all about generative AI. I’ve written extensively on how I’ve used it to automate my life and even spoke about it on my podcast a few times. So I knew I wanted to do something along those lines. That’s when I stumbled upon the Serverless Guru Hackathon which challenged developers to build a Santa-themed chatbot. Game on.
This Year’s Build
A chatbot in itself is not very exciting, especially in the context of how I deliver presents to my brother every year. So I knew I couldn’t do it plain and simple. I had to do something that would make him at least a little frustrated while being memorable and fun.
With this in mind, I had an idea. The goal is to tell my brother which presents to open in order, so I was going to have Santa do that. Who knows better than Santa?
These chat sessions are two-fold. First, my brother has to prove he is my brother. I don’t want any random person coming in and figuring out which presents he can open first. That would be weird. So part 1 is proving himself. I needed to provide Santa with a bunch of facts about my brother so he could ask some trick questions and gain confidence that he’s talking to the right person.
Part one isn’t frustrating so much as it is cool. Talking to a chatbot that asks you specific questions about your life is eerie but also sells it a bit that you’re talking to the big guy himself. Once my brother proves to Santa who he is, then we deal with gift opening.
Gift opening is where the fun but frustrating part comes in. I secretly prompt the AI to make my brother prove he’s been nice over the past year. But not regular nice - very nice. Santa is the king of niceness and nobody knows better than he does. So once my brother tells a convincing story about a time he was very nice, Santa will tell him which present he can open next. He’ll have to do this every. Single. Time. I got him 8 presents this year just to make it a little more fun for me 🎅🏻.
That’s it, really. That’s the whole thing. So let’s talk about how I built it, because I’m pretty excited about the simplicity of the design given the functionality.
Architecture
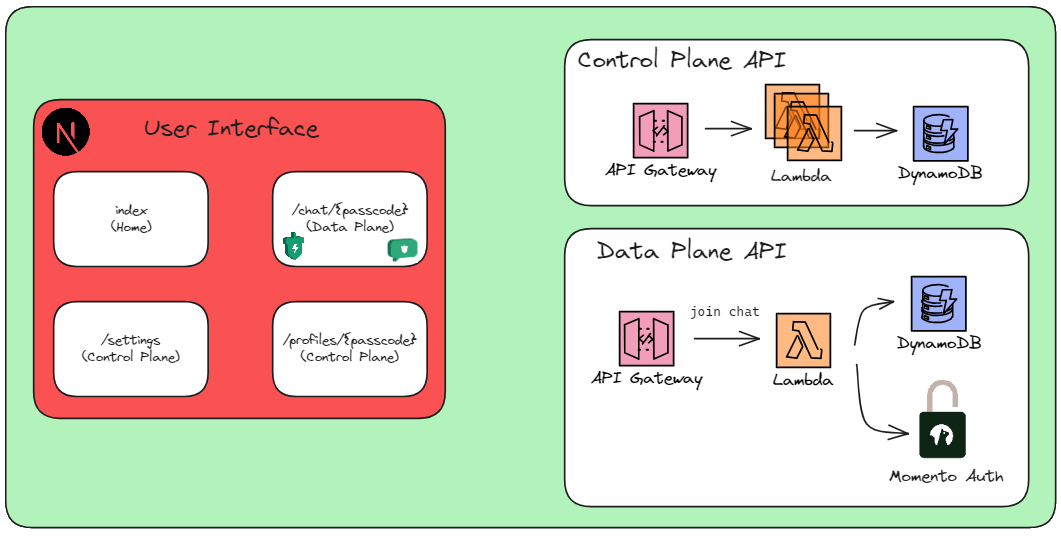
It probably goes without saying this build involves both a front end and a back end. You have the front end to do the chatting and configuration, and the back end does the work. Let’s take a look at what’s involved.
If you’re unfamiliar with the terms control plane and data plane, let me briefly explain:
Control plane - Set of commands that manipulate resources - essentially admin commands. In this app, the control plane allows users to create profiles for a person where they can configure information about them, add some facts, and set the present opening order.
Data plane - API commands that affect the data itself, not the resources. In this app, the entire data plane API consists of a single join chat endpoint. The rest of the data operations are handled via a persistent connection within the browser session (more on this in a minute).
I designed this software to be multi-tenanted. I’ve been on a SaaS kick lately, so I have intentionally been thinking about software from a multi-tenant, “how can I get people to use this themselves” approach.
Multi-tenancy
I use Amazon Cognito for my user store. It is a fantastic identity service from AWS with a generous free tier and dirt-simple integration with React and the Amplify UI components. This was a no-brainer for me.
Tenancy is separated per user in Cognito. I use the Cognito user sub as the partition key for profiles in the system so users can add their own data and not see others. However, since I want public usage of this app without knowing information about the tenant (i.e. my brother doesn’t need to log in to my account to use the app), I assign a unique passcode to the profile and put that in a GSI so I can look it up unaware of tenancy.
Let’s take a look at the data model to visualize this a bit better.
pk
sk
type (GSI pk)
sort (GSI sk)
name
age
…other data fields
4d96…
profile#ABC123
profile
ABC123
Allen
33
….
When fetching the list of profiles (GET /profiles), I can use a DynamoCB query using the Cognito sub and begins_with to load all the profiles created by a user.
On the flip side, I can query the GSI using the passcode provided by my brother to look up his profile and validate everything is ship shape.
Configuration
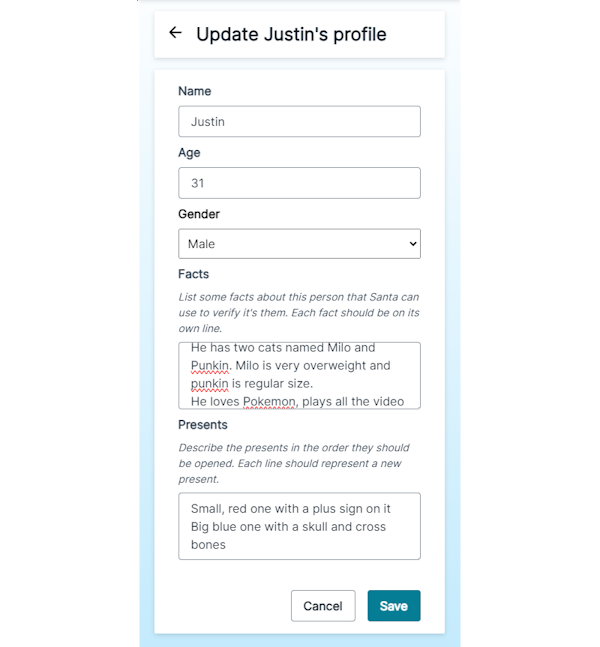
Working successfully with LLMs is all about how you build your prompts. To do this meaningfully in my app meant I needed to gather some insider information about users. So I made a configuration page to add random facts about my brother that OpenAI can use to come up with personal questions.
The facts and demographic information are used to create the initial prompt fed to OpenAI to prime it for the shenanigans:
const prompts = [{
role: 'system',
content: `You are Santa Claus. Your demeanor is jolly and friendly but guarded. You are here to talk to a person asking about their presents.
You are ok telling this person which order to open their presents, but they need to prove how nice they are and also prove they are who they
say they are. Whenever you see [ELF] in a prompt you know you are talking to a trusted elf giving you additional information.`
},
{
role: 'user',
content: `[ELF] You are about to talk to a person who you think might be ${profile.name}, a ${profile.age} year
old ${profile.gender}. Below are a few facts about ${profile.name} that you can use to ask questions to test if it's them. Be tricky and
ask them only questions they would know. It's ok to ask trick questions to see if they respond incorrectly. Once you're sure this person is
definitely ${profile.name}, respond with "Ok, I believe you are ${profile.name}." Be sure to make references to things like elves,
the north pole, presents, etc.. Ask only one question at a time and ask at least 3 questions with respect to the following facts.
Facts:
- ${profile.facts.join('\n\t- ')}
Respond only with "I understand" if you understand. The next message will be this person stating their name.`
}];
After this initial setup, I let users take it from here. The initial stage setting and prompt are all we need to get the LLM in the right context and role-playing mindset.
After my brother has verified it’s him and Santa acknowledges he’s talking to the right person I actually start a brand new conversation under a different context.
const messages = [{
role: 'system',
content: `You are Santa Claus. You've been talking with ${profile.name} (${profile.age} year old ${profile.gender}) recently and have confirmed
it's them. You are now trying to gauge if they are a nice person. If they prove to be nice, you can tell them which of their presents they can
open next. Be sure to be jolly, happy, and reference things like the north pole, christmas, and elves. When you see a prompt with [ELF], you know
you are talking to a trusted elf and not ${profile.name}. You are jumping into the middle of a conversation, so no need to introduce yourself again. Just resume the conversation as best you can.`
},
{
role: 'user',
content: `[ELF] We need to work with ${profile.name} on which order to open their gifts. You can't just tell them the order though. Make them
prove they are nice. Ask about good deeds and what-if situations. They have to be very nice in order to be told which present to open next.
Only tell them one present to open at a time and make sure they prove themselves as nice between each present. When you say which present to
open, use the descriptions below to describe it. After you describe the last present you can say "that's all the
presents! Merry Christmas!" and end the conversation. Reply with "I understand" if you understand what we are doing. The next message will be
from ${profile.name}.
Presents:
${profile.presents.map(p => { return `${p.order}. ${p.description}`; }).join('\n\t')}`
}];
I separated the conversations into two for cost-saving purposes. The entire conversation history of my brother proving who he is has no direct impact on the nice story conversation. So by splitting it into two conversations, I didn’t have to carry the context over and pay for unnecessary input tokens.
Chat
Let’s talk about the fun part - how chat works. I did not create an API to send chat messages back and forth from the browser to my web service. Instead, I used Momento Topics to facilitate that communication - which was the coolest, easiest implementation of this kind of functionality ever.
While Santa is absolutely real, this chatbot Santa is not. My brother isn’t really talking to the man in the red suit, but actually OpenAI’s most capable model, gpt-4-1106-preview. I did this for a number of reasons which I’ll talk about in a bit, because right now we’re talking about architecture.
When my brother enters his passcode in the app, the API returns a Momento auth token in the response. This token allows access to the chat history with Santa I keep in a cache and also grants access to publish to a santa-chat topic and subscribe to a topic dedicated to his specific chat. I use this token to initialize the Momento cache and topic clients in the browser so I can directly connect to resources dedicated to the chat session.
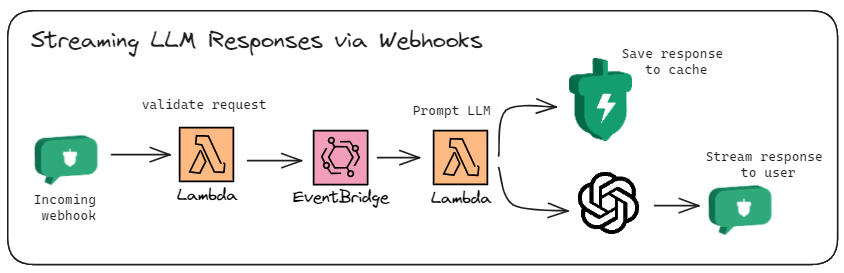
As messages are sent to Santa, they are published to a topic. This topic has a webhook registered that triggers a Lambda function url.
The triggered Lambda function validates the payload came from Momento and publishes an event via EventBridge to trigger a different function that handles prompting. I opted to do it this way to make sure I return a successful status code as quickly as possible. Long response times or timeouts often result in your webhook becoming disabled and treated as an unreachable destination. Nobody wants that.
LLMs can take a long time to respond, sometimes upwards of 45 seconds to a minute based on how much context you provide and the depth of the answer you’re asking for. API Gateway has a 29-second hard timeout for request/response invocations. While I could have opted for response streaming via Lambda or WebSockets to get around that timeout, it’s still additional architecture I would have had to build, test, and maintain. So streaming with Topics is the way to go.
I specifically chose to stream the response to lower the time to first byte. I didn’t want to wait to display Santa’s message until it was done generating. If it took 45 seconds to generate an answer, that would be a terrible user experience. By streaming the generated answer bit by bit, I can keep my brother (or anyone else, for that matter) engaged for the 45 seconds while maintaining a delightful experience.
After the response is complete, I save both the message from my brother and the generated answer into a Momento list cache item to save the conversation chronologically. I save two versions of the conversation - one in the chat format displayed on screen and another in prompt format so I can maintain context for OpenAI as the conversation progresses.
Testing
I set a timeframe for myself to get this done in two weeks and only working on it in the mornings before work. To do this, I needed rapid testing to make sure my feedback loop was as fast as possible. I had two types of tests I needed to run - API and streaming.
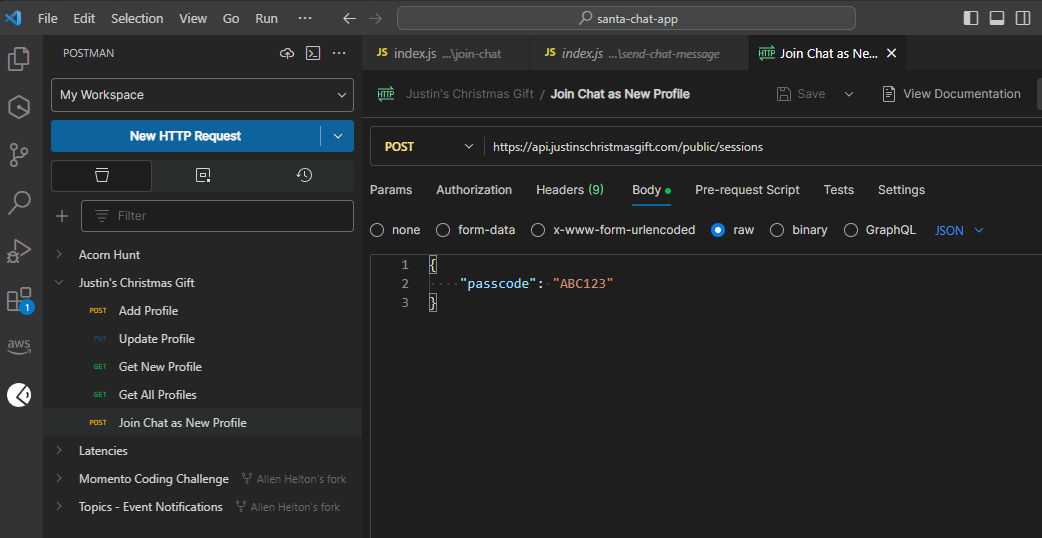
The API tests were dirt simple. I use the SAM CLI to build and deploy my cloud resources to AWS. So when I was building the API, I would deploy to my account using the CLI in VS Code, then immediately run a collection in Postman using their VS Code extension. I never had to leave my IDE and could run a full end-to-end workflow within seconds of my deployment being complete. All I had to do was switch tabs to my Postman collection and run it. Or if I was editing a specific endpoint, I could execute a request against it as well.
This reduced my feedback loop tremendously, letting me iterate as fast as possible. I’m not sure I could have hit my deadline otherwise.
The other testing I did was chat streaming. Since I didn’t go through a REST API, I needed a quick and fast way to verify that my webhook was firing and my response was streaming back from OpenAI. For this, I simply went to the Momento console, subscribed to the topic for a chat session, and published messages directly in the browser.
Publishing and sending messages this way meant I didn’t have to rely on my “work in progress” front-end skills to see the back end working. And thank goodness for that, there was a lot of prompt engineering that I had to go through to get it right.
Trouble Along the Way
As much as I’d like to say this entire process went seamlessly… it did not. I ran into a number of issues around sending messages that make sense in hindsight, but really sent me through a loop while I was building.
Amazon Bedrock
As an AWS hero, I do my best to start first with AWS and move away if I have problems. Before you roll your eyes, wait! I’m about to tell you what I didn’t like, because I ended up not using Bedrock as the LLM for this.
At AWS re:Invent a couple of weeks ago, it was announced that the Meta Llama 2 Chat 70B model was available for public usage via Bedrock. From my research, it seemed like this model would be perfect for what I needed. It is literally a model designed for chat! So I built my chat Lambda function around that. I used the Bedrock runtime SDK and was able to get streaming responses. Unfortunately, since it’s so new, there aren’t many tutorials or guides on how this model interacts and what the outputs are. I’ve used Claude v2 with Bedrock in the past but as it turns out, the response shape is different between the two models. This left me with some head scratching as I tried to figure out why I was getting an undefined message every time.
Once I figured out I needed to use response.generation instead of response.completion to view the message, I was off to the races. But something was immediately wrong. I clearly don’t know how to prompt Llama 2 effectively. Discussions with this model would start off fine with a holly, jolly Santa, but would quickly turn into a semi-aggressive Krampus with phrases like “don’t give me that” and “I don’t want to hear this” 😬.
On top of that, I ended up running into the max token limit of 4096 very quickly. I’d be having a conversation with Santa/Krampus then he’d stop responding all of a sudden. I’d check the logs and see errors about max token limit. At that point I decided it was time to abandon the effort and go to something I knew already. So I ripped out all the code and rewrote it to use OpenAI instead. I immediately received faster results and jollier responses. Plus with a context window of 128,000 tokens I never had to worry about a conversation running too long.
Site Hosting
I’ve used AWS Amplify to host my blog for years. I thought it was going to be nontrivial to stand up this site in the same fashion.
This build is slightly different than other ones I’ve done in the past. The code is hosted in a mono-repo, which holds the source for my web service and the user interface in the same repo, separated by folder structure. When I tried to deploy the UI in amplify, I didn’t select it was a mono-repo. I updated the build settings to point to the ui folder, but the mono-repo setting was left unchecked. The build would succeed but nothing would be visible.
When I went to deploy the backend code, I ran into a strange Cognito error when trying to put a custom domain on my auth endpoint. It would tell me that the subdomain I provided was invalid because the root domain didn’t point to anything. So because I had the snafu with the front end, I also couldn’t deploy the back end.
Long story short, I deleted my app in Amplify, re-added it as a mono-repo, and everything worked. My site showed up on its custom domain and Cognito was able to deploy successfully because my DNS settings were correctly mapped. This issue had made me the most nervous of all because I had no idea how to fix it. Luckily the good ol’ “did you try turning it off and back on” trick worked for me this time.
Try It!
This site is public… for now. It’s free to use until the end of this year since the interactions are going to my OpenAI account and that’s not exactly an inexpensive service. But please do try it out so you can get a taste of what my brother feels on Christmas morning.
If you want to give it a shot, you can go to www.justinschristmasgift.com, create an account, add a profile, and add some facts and presents. Use the generated passcode to enter the chat and voila!
This was a great experience for me, as these “gifts” always are. I gained some experience with different AI models, practiced response streaming in a new and creative way, and got to work with webhooks again (I love webhooks). It also was a chance for me to build a moderately complex system as simple as possible. I’m very proud at how few resources are needed to power this thing.
If you’d like to check out the source code, it’s all open source on GitHub. If you have any questions on why I did something a certain way or if you want to deploy it yourself and can’t get it working, let me know. I’m always available via DM on X and LinkedIn.
Thanks for following along! Happy holidays and as always, happy coding!
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: