
Application development

Power Tuning Your Serverless API For Happy Customers
APIs are digital currency.
Modern software lives and breathes through the use of APIs. It’s how things work today.
Not all APIs are created equal. Simply having an API is not going to bring you happy customers. Having a high-quality, meaningful API is what sets you up for success.
But how do you increase the value of your API? What makes an API high-quality?
Honestly, it depends on the lens you’re looking through. Arguably the most important way you can look at your API is through the eyes of the customer.
Whether they are using a UI that sits on top of your API or are an integrator, an impression of the quality of your API is made real fast.
What Is High-Quality to Consumers?
Do you remember the last time you were on a website, you clicked a button, and your cursor just spun and spun? After what seemed like forever (but was actually 4 or 5 seconds) the page loaded and you continued what you were doing.
That didn’t leave a very good impression, did it?
Especially if it was the first thing you did on that website. Your API needs to be fast. Consistently fast. If an API returns in less than .5 seconds, it feels normal. Between .5 and 1 second, your consumers will notice. Over 1 second and your consumers will start getting antsy.
Speed is the most important factor to consumers.
New scenario: remember the last time you went to a website, clicked on a button, and were navigated to an ‘Oops, something went wrong’ page? Hopefully the page had something cutesy on it, like what Amazon does when something goes wrong.
 Friendly Amazon error page
Friendly Amazon error page
You hit the back button to try again. It works this time.
What you had was an unreliable experience. You expect it to just work, yet you got to an error page and had to go back and do your task all over again.
If that happens more than once you’re going to begin rethinking your choice to use that site. You want an API that will perform the same over and over and over again.
Consistency is the second most important factor to consumers.
How to Identify Optimizations
Every developer has heard it before. Your product owner asks you “which features are the customer using the most?”
Traditionally this kind of thing could be done by adding invasive tooling into your controllers to track hit count and latency. You’d either purchase a third party license to gather the data and give you insights or you’d build it all from scratch instead of enhancing the product.
Knowing your most used features is critical for happy customers. There’s a reason product owners always ask about it.
It tells where to focus your energy, helps you figure out in your UI where the most heavily used pages are, and identifies any features that might need to be removed.
With serverless, you get these insights for free. Take the architecture diagram of my fake-business-but-real-serverless-API below as an example.
 Diagram of a simple serverless API
Diagram of a simple serverless API
Each endpoint is tied to an individual function. Every time the endpoint is called, services like AWS CloudWatch or Azure Monitor will log metrics like number of invocations and execution time.
Built-in analytics not only tell you invocations and execution time, but also metrics like concurrent executions, throttled attempts, and http status codes. With these metrics broken down on an endpoint level you can see which functions get burst executions in times of high traffic. In addition, you can see how well your functions handle the bursts by looking at success vs failure status codes.
As a result, these managed services can tell you how to identify which features in your API are used the most. The most used features deserve the most attention and enhancements. Any slow-moving, frequently-used endpoints move straight to the top of the priority list.
But after you identify where your optimizations should be, how do you know what changes to make?
Speeding Up Slow Endpoints
We’ve already established the two primary characteristics of happy customer API: speed and reliability. Serverless provides developers with the tools to build APIs with unrivaled latency and consistency. When it comes to speed, there are a couple different ways you approach it.
Increase Resource Allocation
Compared to other architectures, serverless provides developers with incredible fine-grained control. Settings may be configured for each endpoint, meaning once you identify the slow functions you can allocate specific resources to speed them up.
For example, take Gopher Holes Unlimited and some of its endpoints:
- POST /gophers
- GET /gophers
- PUT /gophers/{id}
- POST /gophers/{id}/statuses
- POST /holes
If the POST /gophers endpoint is slow, a simple fix is to increase allocated memory to the function backing it. With AWS, you explicitly state how much memory each function is allowed to use during runtime. Bumping that up from the default 128 MB to a healthy 768 MB will ensure the function runs faster.
Of course you can always look for optimizations in the code to speed it up, but that’s true regardless of your implementation. Serverless gets the advantage here for resource allocation at the endpoint level instead of at the controller level.
Change The Integration Type
Serverless also provides you with integration options. This means that your API doesn’t even have to use a function. It is possible to have your API Gateway query your database directly and bypass code altogether.
If your endpoints are as simple as load from the database and transform the data shape, proxying directly to the database can save an incredible amount of time (not to mention cost!).
Going straight to the database will prevent cold starts, reduce the number of services required to execute an endpoint, and eliminate extra code. The fewer lines of code, the fewer opportunities for a defect.
From a code perspective, your endpoint cannot get faster if there is no middle man (a function). Data validations are done in your Open API Spec and transforms are done directly in your API Gateway.
Your API could be a mix of endpoints that go straight to the database, endpoints that use a function, and endpoints that call other endpoints. With serverless, it doesn’t matter. You control the implementation of every single one in your API.
Improving Reliability on Critical Endpoints
The other primary factor for keeping customers happy is reliability. You want the API to perform the same day after day after day. You want the experience to be the same whether you have one active user or one million.
You don’t want the Reddit hug of death taking your site or API down.
Again, serverless provides us with a couple different paths to help establish reliable performance.
Configuring Provisioned Concurrency
Provisioned concurrency is a fancy way of saying “make sure I have functions warm at all times.” There are many scenarios where cold start times are unacceptable and cause significant detriment to the user.
With serverless APIs, any critical endpoints may be configured to be ready to go at a moment’s notice. With provisioned concurrency, you guarantee you have functions ready. It is even auto-scalable, meaning if there is a prolonged burst of traffic that hits your API, you can keep a large number of functions warm/ready to fulfill requests. When the traffic dies down, it scales back down to meet the lower demand.
Without a doubt, there will be some endpoints in your API that are used significantly more than others. The 80/20 rule states that 20% of your features will be used 80% of the time. To maintain happy customers be sure to tune your endpoints to allow for provisioned concurrency where it counts. Keep the responses snappy, fast, and reliable.
Setting Up Fault Tolerance
For systems like CAD (Computer Aided Dispatch) where emergency services must be connected and ready to go in milliseconds, downtime is not tolerable. If the system is down, people’s lives are at risk.
For critical endpoints that cannot be down, like routing emergency vehicles, serverless provides a way to easily build in fault tolerance. If a region in your cloud provider is down, you can configure your serverless solution to automatically failover to a different region.
Standard failover configurations are actually not unique to serverless. You would deploy your API into multiple regions and configure DNS settings to route the the appropriate region based on geolocation or ping from a health check endpoint.
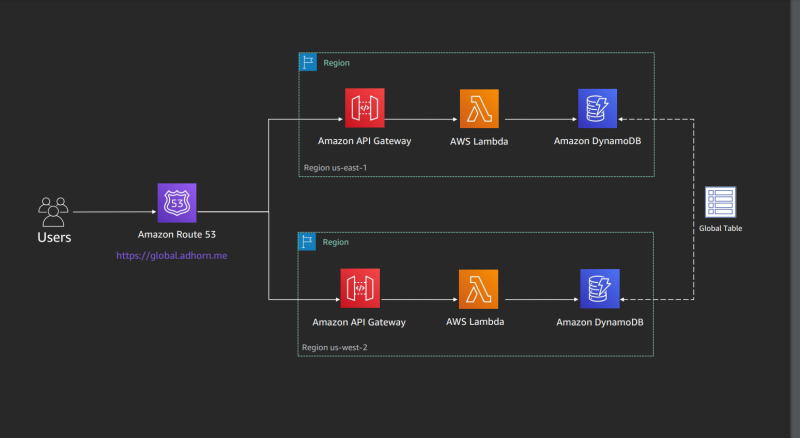 DNS multi-region failover diagram
DNS multi-region failover diagram
Another reason to proxy your APIs straight from API Gateway to the database is to remove the opportunity of an outage affecting you. If you take out the AWS Lambda or Azure Function piece in the middle, your API will still work if that managed service experiences an outage.
The fewer moving parts, the better speed and reliability you will have.
Get Started
If you haven’t already, go out to the monitoring service in your cloud provider and build a dashboard to view your API analytics. Figure out what the most used endpoints are in your APIs. Determine where your focus should be.
Identify the slow areas of your application. Can you speed them up by allocating more resources? Are you able to cut out the function entirely?
Does a specific endpoint need to be warm all the time? Which part of your API receives the most burst traffic?
You have options to provide the best experience possible. At the end of the day all we really want are happy customers, right?
Hone the resources, build in fault tolerance, and involve as few services as possible. If you can pull that off, you will have a beautifully power-tuned API that will bring you happy customers.


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.