
Application development

The Challenges of Stateless Architecture: How to Monitor Your Serverless Application
So you decided to go serverless. Congrats! Welcome to the land of high availability, vertical and horizontal scalability, rapid development, and pay for what you use.
Business functionality is the name of the game. Software engineers get to spend their time solving business problems instead of solving networking and infrastructure problems. Your application is going to have full focus from the development team.
But with serverless apps come some new and interesting challenges. Challenges that before have been solved problems.
Problems like how to forecast application costs. Since your application is pay for what you use, how does that translate to number of executions and compute time?
Or problems like how to test your application at scale. How do you test all those lambda functions, API Gateway endpoints, and SNS Topics?
How about application health? You need to know if your application is up and running and doing what it’s supposed to be doing. Traditional development had an easy answer to this problem. Just add a health check endpoint. Create a web service that checks that status of your servers and their connectivity.
But what if your app doesn’t have servers? A serverless application is stateless. It’s distributed. You don’t control the servers your code runs on. Heck, most of the time, your code isn’t even running!
 Photo by Sebastian Herman on Unsplash
Photo by Sebastian Herman on Unsplash
Get to Know Your Serverless Issues
You’re going to have different issues with a serverless application than with a traditional client/server or even containerized application. Believe it or not, your days of did you try turning it off and on again are now over. There’s nothing to turn off.
When an AWS Lambda function is invoked, a small firecracker container is spun up, your code is executed, then it is spun down (unless more invocations quickly follow it). Essentially your entire application is turning itself off and on again all day.
What you are much more likely to see are infrastructure setup issues, configuration problems, and external integration mishaps.
Infrastructure Setup Issues
If you are using a repeatable infrastructure setup script like CloudFormation, there are many tools in place to make sure your serverless app is configured properly.
AWS SAM is a framework that allows you to easily connect serverless components together. It takes the heavy lifting of CloudFormation and abstracts it away into a few lines of YAML or JSON. This allows you to do things like trigger a lambda function when you upload a document to S3, or to build a DynamoDB table in just a few lines.
What it does not do, is validate your IAM permissions. IAM is what AWS uses for identity and access management. If you are following AWS best practices, you are practicing the principle of least privilege (PoLP). Meaning you have set up your roles to only use what they absolutely need.
This sounds great in theory, and ultimately it is a security-minded person’s dream. But in the beginning, it is incredibly hard. Finding the right permissions, knowing when to limit down, and figuring out how to build IAM roles has a bit of a learning curve.
When you’re building your app for the first time, you will run into issues where one service isn’t allowed to talk to another. It’s easily fixable, but it’s bound to show up time and time again.
Configuration Problems
As much as we all like to think we write perfect code, we do not. There will be bugs, and there will be many of them. With serverless applications, these bugs will certainly manifest themselves in configuration issues.
A standard serverless pattern is:
Start Execution > Load Configuration > Do Business Logic > Save Results > Complete Execution
If you don’t have airtight configuration set up, your application is going to go haywire. Take it upon yourself to make sure you log an appropriate amount of details when it comes to saving and loading tenant configuration.
External Integration Mishaps
We’ve all been there. Everything is working great. Your application looks and feels bulletproof.
All of a sudden the wheels have fallen off. Bells and sirens and lights are going off and you have no idea what just happened.
Turns out a third party dependency went down. You rely on them to perform a task, and their application started failing.
Your SLA is only as good as the worst SLA of your dependencies. Be careful when choosing them and have a plan in place when things go south.
Know Your (Soft) Limits
A new problem you have to worry about is hitting soft limits. A soft limit is a constraint put in place by your cloud vendor to make sure you don’t do anything…. stupid.
For example, AWS has a soft limit of 1000 concurrent lambdas running at any given time. If you try to have 1001+ lambdas going at the same time, you will start getting throttled and recieve 429 HTTP responses.
Luckily in this case soft means they are adjustable. If you do run into a situation where you need to update a limit legitimately, you can send an email to AWS support and they will up your limit for you.
 Photo by Chad Peltola on Unsplash
Photo by Chad Peltola on Unsplash
Throw Errors Into DLQs
In a serverless application, you can’t login to an app server to go look at the logs. There are no more persistent connections. App server logs aren’t a thing.
You have CloudWatch logs, but if you’re just browsing, it can be a nightmare to find what you’re looking for. Each lambda that spins up creates its own log group, and over the course of the day you could have thousands of groups to comb through.
You must send errors to a Dead Letter Queue (DLQ). A DLQ is a type of queue where you send exceptions to be reviewed manually. They give you direct access to the details of an error, plus you get context of what your application was doing when the error occurred.
Your serverless application should almost always attempt to retry operations if they fail.
If your retries fail and there’s not a clear path to resolution, take the context and the details of what you’re trying to do, and send it to a specific queue. You should have a separate queue for each failure point in your application.
Yes, that does mean a significant number of queues, but it also means you know exactly what is failing should something show up in there.
Configure DLQ Alarms
In an ideal world, there wouldn’t be any issues.
In a close to ideal world, a software company would identify and fix any issues before the customer reports them.
In order to be aware of issues the moment they happen, you need to set up alarms on your Dead Letter Queues. Alarms monitor DLQs and alert the responsible parties if there are incoming messages.
You can build alarms directly in AWS CloudWatch, or you can use an external service like Datadog to manage them. These services allow you to set alarms on specific Dead Letter Queues, watch for a threshold of incoming messages over a given period of time, and alert the relevant groups of people by sending emails, slack messages, phone calls, etc…
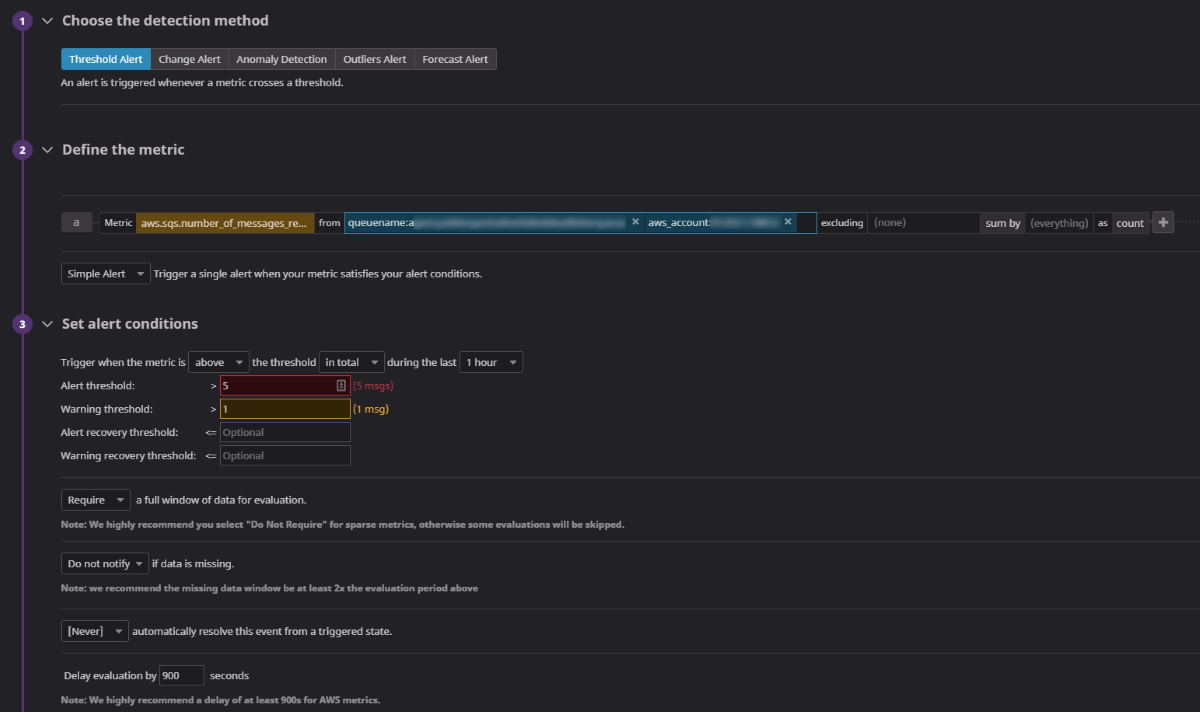 Configuration of a Dead Letter Queue monitor in Datadog
Configuration of a Dead Letter Queue monitor in Datadog
An example alarm for a DLQ would be:
Over the course of an hour:
- If no messages are queued, everything is ok
- If 1-4 messages are queued, raise a warning in Slack that something might be going on
- If 5+ messages are queued, something is wrong - notify the on-call engineers
Once you have a robust set of alarms, you’ll be able to quickly respond to issues as they arise.
Run Automated Business Flows
It’s not realistic to have a QA analyst running tests through your system all the time. But you need tests to make sure the system is healthy and everything is working.
Instead, you can set up automated tests to exercise your application and have them run periodically.
 Photo by Filtore F on Unsplash
Photo by Filtore F on Unsplash
With Postman, you can build workflows that simulate users in your system. You can record all the web requests your application makes in a business flow, parameterize them, and have them play back with random values at regular intervals.
On one of my projects, we configured these workflows, called collections to run in our test and prod environments. We had a full suite of workflows that tested the entirety of the system that would run every 4 hours in our test environment, and every 2 hours in production.
The collections run a series of web requests and then execute tests to verify things like status code, response times, and expected response schemas are correct.
With the system doing self checks like this every couple of hours, we had the confidence the system was operational at all times.
In the event tests do go wrong, we had reporting through a native integration with Datadog that would send the team a message in Slack for immediate action.
If you build up these collections, not only will you get the confidence your system is operational, but you also set yourself up for easy load testing.
Try Managed Monitoring
There are many native tools to monitor your serverless applications. You configure your dashboards, tests, alarms, notifications, limits, thresholds, etc…, but you still have to maintain all the data you’re collecting.
An alternative to building it yourself is trying out a managed monitoring service like Datadog, Thundra, or Epsagon. Not only do services like this give you enhanced monitoring data, but they also gives you observability of your assembled system by drawing out your architecture diagrams.
Having visual architecture diagrams and infrastructure graphs help with issues like spotting bottlenecks and other throttling opportunities.
In the event things do go wrong, a managed monitoring service will also provide enhanced debugging measures. The faster you can debug, the faster you can get your system operational again.
Conclusion
Often thought of a little too late, monitoring a serverless application is a necessary part of application development.
It provides insights into your system, aids in troubleshooting, and gives you confidence your setup is correct.
Take the time to set yourself up with the tools to find issues before your customers do. Send all your errors to Dead Letter Queues. Trigger alarms when errors get there. Whether you set them up manually or with a managed service, your future self will thank you.
Build automation wherever you can. Make your system reliable. Feel confident you’ve built the right software.
Most importantly, let your developers focus on development. Having a fully monitored system allows them to put their efforts in what really counts - solving business problems.


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.