
Proof of concept

How to Build Both Kinds of AWS Lambda Layers. (Yes, There Are Two)
I first started out with serverless programming about a year ago. I came from an enterprise software background with giant applications and spaghetti code. If I changed some code that modified the UI, there was a possibility it was going to affect something at the database level. Yikes!
I had in my mind that code was meant to be reused and shared. It kind of made sense to just write it once and call it from everywhere. When I started building my first proof of concept with Lambda, I made an assumption that I could do the same thing.
I built my solution in VS Code, with each Lambda in its own folder and a shared folder for all my base classes and reusable functions.
Worked great on my local machine. Then all hell broke loose when I hit deploy.
Nothing worked. I got “method not found” exceptions everywhere. I started to think that cloud development might not be as easy as everyone says it is.
When you deploy a Lambda function to the cloud, it must have all of the dependencies bundled with it. If you use AWS SAM, it takes everything contained in the root folder of the Lambda. That’s it, nothing else.
Shared dependencies do not live in the root folder, they live in a shared folder so all functions can access them via the same path. How am I supposed to get around this?
You Have Options
 Photo by Kelly Sikkema on Unsplash
Photo by Kelly Sikkema on Unsplash
There are three ways you can get around this issue:
- Duplicate the code in every lambda directory that needs it
- Create a package (npm, nuget, PyPi) and install it as a dependency
- Use a Lambda layer
We aren’t going to talk about the first option. It’s in there because technically it is a solution to the problem, but it is not scalable. At all.
Creating a package isn’t a bad idea. If you need to share code across microservices, it’s actually a really good idea. If you’re just sharing code within the same microservice, it might be a little overkill. However, if you want to make your code open source and share it with the world, I’m all for that!
We’re here today to talk about the third option: Lambda layers. A layer is just another bundle of code that sits alongside your primary Lambda function. They are reusable chunks that can be shared across as many Lambdas as you want, even across accounts.
The Two Types of Layers
Believe it or not, there are actually two different types of layers. Technically, there is only one, if you look at the deployed resource type. But looking at them in practice, there are two very different use cases for layers.
Dependency layers
A dependency layer is strictly a package that contains third-party dependencies for your Lambda functions. Many packages out there are large, take a while to load, and bloat your function code. By moving all of the dependencies into a shared Lambda layer, you can offload the bulk of the deployment package, keeping your function code-focused and concise.
Function layers
This was my original use case for layers. What if you want to share code across multiple functions? Developers are past the WET (“We enjoy typing”) era of code writing. It would be nice if we could write the function once and access it in all of our Lambdas. This way, if we need to change something in a piece of reusable code, we can change it in one place and it updates everywhere. Woohoo!
Developer Ride-Along
 Photo by Alvaro Reyes on Unsplash
Photo by Alvaro Reyes on Unsplash
It can be a little abstract following a guide on Medium. I’ve provided a complete working solution on GitHub for you to walk through with me.
Working examples have always helped me the most to get a hands-on approach to a problem. You might want to pause here to follow the prerequisites and make sure you’re set up.
The example I’ve provided is a small, serverless API that manages contacts and allows you to send them text messages through Twilio. You can add, update, and delete contacts, as well as send and view the messages that have gone to each contact.
Build a dependency layer
As stated before, dependency layers are useful for keeping your deployment packages small. A big situation in which this is helpful is if you have any expectation of using the AWS console to do any quick troubleshooting.
If a Lambda deployment package is larger than 3 MB, you cannot edit the code in the console.
So for our dependency layer in our contact example, we have a folder called dependencies at the root with a subfolder of nodejs. Lambda looks in specific directories for layer code based on the runtime. Since we are using Node in the example, we simply have to add a folder called nodejs.
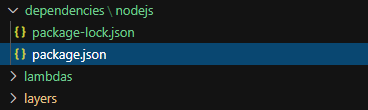
For the complete list of all the directory names based on runtime, you can view the AWS documentation.
All we have in the nodejs folder is a package.json and a package-lock.json.
The package.json will only contain the dependencies we want to add in our layer.
In our SAM template, we want to add a LayerVersion and point it to the dependencies directory
That’s it for creating a dependency layer — super easy implementation, but not necessarily intuitive. Now on to creating a function layer.
Build a function layer
You might have more use cases for this type of layer, the layer that gives you the ability to provide shared code throughout your solution. This one is laid out similarly, but the consumption is slightly different.
Create a folder structure in the root called layers > nodejs. Again, the subfolder is because of the runtime we are using. It will be different for you if you are using Python, Ruby, etc.
Add the package.json and any file that is going to contain shared code. For our example, we have a database.js and an enums.js file.
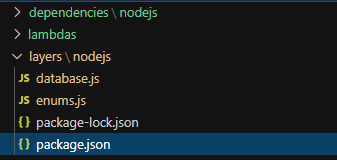
Every file you add in this directory is a separate import in your Lambdas. This is nice because you get a reasonable separation of concerns for your shared code. It helps you stay a little more organized.
The resource declaration in the template yaml is going to be identical to the dependency layer, only this time it will point to the layers folder.
The implementation of the two types of layers is very similar, the only real difference being the files added to the layer directory. The main discrepancy between the two is how they are consumed by your functions.
Consuming a dependency layer
To make your layer available for consumption for a Lambda, you need to add it in the template yaml. If you want your layer available to all functions in your microservice, you can conveniently add it to the Globals section.
After you’ve made the layer available to the function, you need to pull the assets in. With dependency layers, it’s business as usual: simply add your require statement to pull it in. There is no change to how you build your function code.
Consuming a function layer
This is where your development will change slightly. Function layers get deployed to an opt directory, so to pull in your code, you must pull from opt/nodejs/<your filename>.
Each file you want to import can be its own require statement. You can also have the files reference each other in the function layer. You can see an example of that in the [database.js](https://github.com/allenheltondev/aws-lambda-layer-types/blob/master/layers/nodejs/database.js) file of the solution.
Things to Watch Out For
Lambda layers are great, but there are a couple of things to watch out for.
- You cannot import a layer from another microservice locally — If you do your tests locally before pushing into the cloud, you cannot download a layer via an import and expect it to work. That is currently a gap in the layer process. If the layer is in the service you’re working in, everything works great.
- SAM does not build layers — You are going to have to manually do an npm install on each of your layers in your CI/CD pipeline. SAM will package up and deploy a built layer for you, but it does not do the build.
Conclusion
Layers are great for sharing code and keeping deployment package sizes down. They are lighter weight than creating your own npm package and easier to maintain, too.
Remember, they are best used in the same microservice as your Lambdas, and the folder structure depends on the runtime you are using.
Feel free to take the example I provided and make it your own. It makes use of Open API 3.0 and the new AWS HTTP API. Keep your skills sharp, and stay up to date with the latest and greatest in the AWS serverless tech stack.
#SmarterEveryDay


Share on:
Join the Ready, Set, Cloud Picks of the Week
Thank you for subscribing! Check your inbox to confirm.
View past issues. | Read the latest posts.