AppSync Events Are Great, But Did You Really Need Serverless WebSockets?
By Allen Helton17 December 2024 • updated on 12 January 2026
Listen to me read this!
A few years ago I was the tech lead on an digital evidence application. The app had multiple personas as actors, all of whom would be interacting with evidence at the same time. We got an early version of it out the door and were quickly met with a feature request to keep changes in sync whenever an actor would comment/redact/categorize something.
I said “Sure, I’ve always wanted to implement WebSockets!”
😑😑😑
That was a mistake. Everything about it was a mistake - my assumption that the requirement meant WebSockets, the fact that I wanted to implement it, and my gross misunderstanding of the “simplicity” of real-time communications.
I blame myself. I didn’t know any better. I was the first one in the company to tackle this type of feature. Nobody heard what I was doing and said “Bless your heart”. But you know what? I know better now. But it took a lot of effort, mistakes, intentional learning, and maintenance frustrations to get where I am today.
Which is why I’m writing this - to help you skip a few steps and get you to a better understanding of what real-time communication is and what you really want from it. There’s recently been a newcomer to the WebSocket game - AppSync events. While it is significantly better than anything we’ve had from AWS in the past for managed real-time communication services, it’s still a long way off from ideal.
I actually think the problem here is education. For years the tech community has been asking for managed WebSockets. And credit to the AppSync team, that is exactly what we got. But I don’t think that’s what we actually wanted. There’s so much that goes into delivering a message from a publisher to a subscriber, and WebSockets are really only a tiny portion of that. What we want is something that’s managed from end to end.
So let’s talk about what you really want and measure up AppSync events (which is a legitimately solid service) next to it.
WebSockets vs PubSub
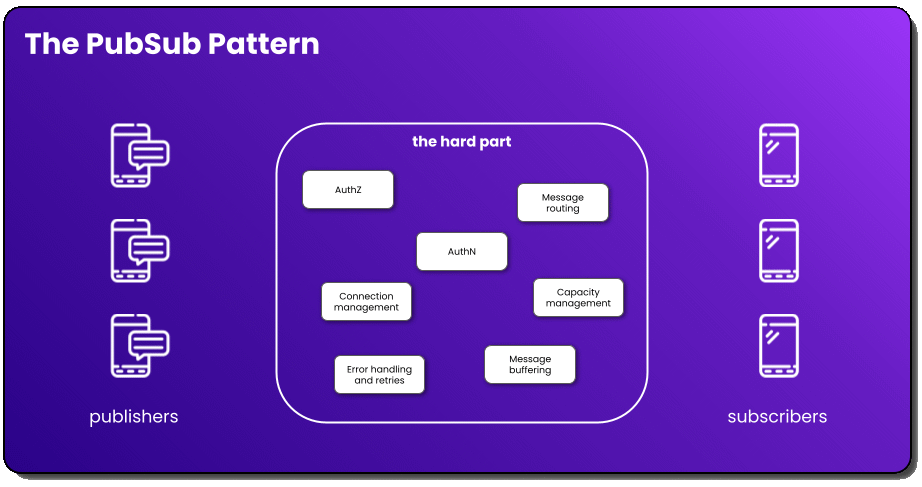
All too often, developers freely say WebSockets when they actually mean PubSub. When they say WebSockets, most of the time they are referring to the communication pattern between a client and a server (PubSub!). Thinking about this communication pattern naively, like when I implemented it the first time, it feels like it should be two things: publishers and subscribers. You have entities that send, or publish, messages and other entities that receive, or subscribe, to them.
But there’s a bit more to it than that.
You have authentication, authorization, message routing, connection management, capacity management, error handling/retries, and message buffering in a complete solution. These aren’t things that are quick, 1 story point tasks on your sprint board either. They require intentional design, low-level engineering skills, and knowledge of your traffic patterns. In the age of serverless and the just do it for me mentality, this is a lot of undifferentiated heavy lifting.
So where does that leave WebSockets? Well, WebSockets is an implementation detail. It’s literally a communication mechanism for message delivery between a client and a server.
When talking about sending messages from a server to a client or keeping data in sync between all sessions in a collaborative game/app, WebSockets could be the communication mechanism, but what we’re really referring to technically is the PubSub pattern.
PubSub options in AWS
As I mentioned earlier, you have several options in AWS for PubSub. But today we’ll focus on two of the better known options and how they differ from each other.
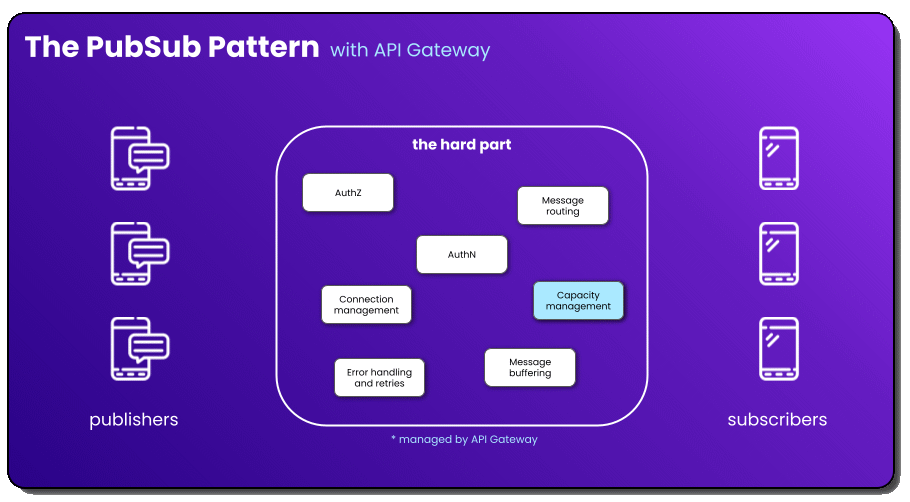
API Gateway WebSockets
If you’ve implemented WebSockets in your app before, you likely did it with API Gateway WebSockets. Launched six years ago, API Gateway WebSockets seems like one of the most popular WebSocket services available in the cloud. When we think about this service with regard to PubSub, there’s a lot to be desired from a “managed” perspective.
While I appreciate the capacity management aspect from AWS, there’s still so much you are responsible for. In fact, the only blog series I’ve ever written was on building a production-ready API Gateway WebSocket implementation. There’s a ton of things you have to control! If you’re a fan of building things yourself and owning maintenance for it, use this.
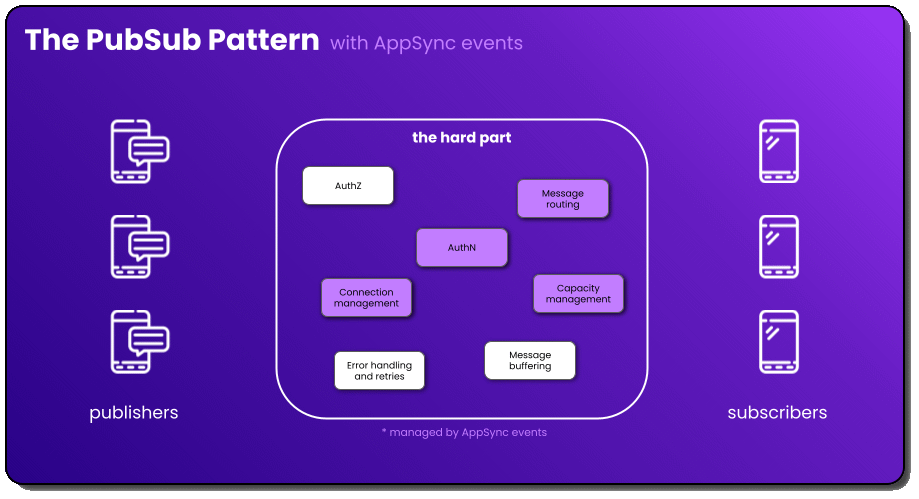
AppSync events
AppSync events, on the other hand, was released in October and marketed as a “serverless WebSocket API” without worrying about building WebSocket infrastructure, managing connection state, and implementing fan-out. This is intriguing to many of us because it’s quite literally what the tech community has been asking for! This service abstracts a lot more of the hard part compared to API Gateway.
I’d argue that they abstracted some of the hardest parts about PubSub, and did a really good job at it. Unfortunately, there’s still a decent amount of work you have to do yourself, and some things you literally can’t do with it. Before I dive into what you can’t do, let me list out some of the great things it does and leave you with some documentation 👍
These are all HUGE steps forward in a managed real-time communication service. Not to mention the IaC has been reduced by almost 50x! Kudos to the team for the forethought and execution 👏
Now let’s talk about the stuff I don’t like.
Things that could be better
I’ll put a disclaimer here - I’m aware the service is early in its life. It will continue to get better and more managed over time. As it does, my opinions will change, that’s the beauty of serverless and managed services.
Authorization
Authentication is “are you who you say you are?” and authorization is “are you allowed to do what you’re trying to do?” Like I mentioned a second ago, AppSync events does authentication really well. But determining what channels you can subscribe to? Not so much.
There is an onSubscribe event handler you can build for auth, but it currently has some limitations. It’s scoped to AppSync JS, which does not allow you to reach out to other AWS services. You’re provided a context object which provides identity information about the user and the channel they are subscribing to, but it’s difficult to scope down to specific channels. Let’s take 2-person chat room as an example.
With a chat room, you would generally use a chat id as your channel name (let’s use ABC123 as an example), so the two people in the chat room both might be subscribing to the /chat/rooms/ABC123 channel.
Unless you are able to add what chat room that person is allowed to use to their identity in the context object (possible, but you’ll have to balance the complexity trade-off), there’s no stopping them from subscribing to a completely different chat (/chat/rooms/XYZ789) and eaves…reading. That said, you can set scope to different namespaces, which might be a valid solution, but namespaces are resources you have to create and maintain in your account. Again, trade-offs.
Error handling and retry
I know all of you serverless developers are familiar with the concept of error handling and retry. Something goes wrong and you gracefully and (hopefully) handle it programmatically so things just keep working without getting developers involved. The AWS SDK does this for you automatically when invoking commands, and you kind of but not really can handle this on your own with AppSync events.
Let’s consider the lifecycle of sending a message in PubSub:
Typically when we think of error handling and retry with communication patterns it’s in the Deliver and Receive phases. These two phases are known as message delivery and are prone to errors and dropped messages. The WebSocket protocol does not have anything built in to help when a message fails to make it to a subscriber. It provides an at-most-once delivery guarantee, which is another way of saying “no guarantee”. This type of error handling has to be done at the application level (AppSync events). Unfortunately, it does nothing for us on event delivery. If it’s lost, it’s lost.
You can, however, do message validation via an optional onPublish handler. Every time a message is published to a given namespace, the handler will run, allowing you to enrich, transform, filter, and validate the content of messages. While I don’t consider this to be a method of error handling, it is a pretty slick feature that you don’t see very often in competitors.
For the sake of completeness, here’s an example of using the onPublish handler to validate messages and return an error:
export function onPublish(ctx) {
return ctx.events.map(event => {
const msg = JSON.parse(event.payload.message);
if(msg.toppings.includes('pineapple')){
event.error = 'Pineapple does not belong on pizza.'
}
})
}
You can see the power in this handler. You can do anything you want to the messages, which opens up the door to many possibilities. But once again, at the time of writing, it’s using AppSync JS, so you’re stuck with the data you have in the context object and can’t reach out to other services in this code.
Message buffering
Message buffering is a concept I never knew I needed until I learned about it. It’s basically a short-term queue for message delivery. When a subscription drops, you need to try to re-establish it. When the connection is back up, what happened to all the messages that were sent when you were disconnected?
They are lost forever, of course.
But with message buffering, those “lost” messages are put into a short-term queue (life of 3-5 seconds, usually), and when the connection is back online, all of the messages are delivered to the subscriber - resulting in minimal data loss. Now, if you have a 5 second message buffer but you were disconnected for 8 seconds, you will have 3 seconds of message loss in there, but generally wavery connections will be back up in less time than that.
Anyway - AppSync events doesn’t do this 😢 Honestly, it’s a really hard problem to solve. They did so much in this first release I can’t blame them for not letting this be a release blocker. I don’t know if it’s coming, but hard to fault them for not having it.
Performance
When talking about real-time communication, you want end-to-end delivery of your messages to be… real time. Now, based on your use case, the perception of real-time can change. For example, if you’re transmitting audio, anything slower than 150ms is a noticeable delay and can disrupt the flow of conversation. For video, you generally want that under 200ms, otherwise it starts to look and feel choppy. For interactive applications, like UI responses and data updates, you want that under 100ms or it won’t feel instantaneous. However, humans are pretty forgiving and will generally accept 100-250ms latency before feeling like they are being disrupted.
I ran two different performance tests under varying amounts of load to see how AppSync events handles traffic spikes to the same channel. Let’s take a peek to see if we have an instant, acceptable, or disruptive experience with the service.
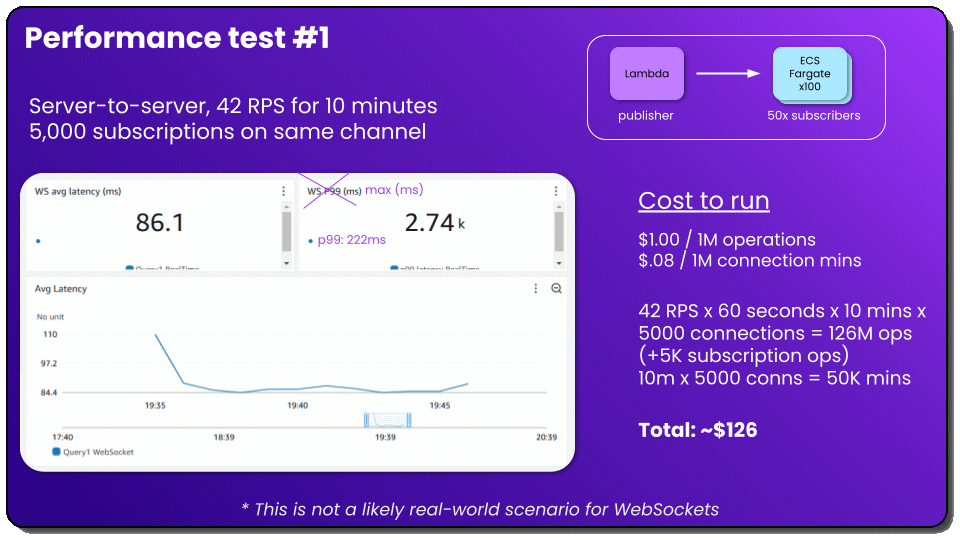
Server-side load test
I wanted to know what the fastest message delivery possible was for AppSync events. So I spun up 100 ECS Fargate instances, each with 50 connections in them, and published messages through Lambda at a rate of 42 requests per second (RPS) for 10 minutes. Going from Lambda to ECS virtually eliminates network latency because data is staying in-region inside of AWS. This lets me see true service latency. But this is not a real use case for AppSync events! It’s intended to be used to connect to end user machines, not to connect backend services. I really just wanted to see what we were working with.
The average latency for these messages was 86ms, well within our instantaneous range. The p99 (or what 99% of the messages completed faster than) was 222ms, skirting in right under our tolerance range, with the single slowest call at 2.74 seconds. Pretty good results overall! Could it be faster? Sure. And with AWS it usually gets faster by itself as the service team makes infrastructure improvements.
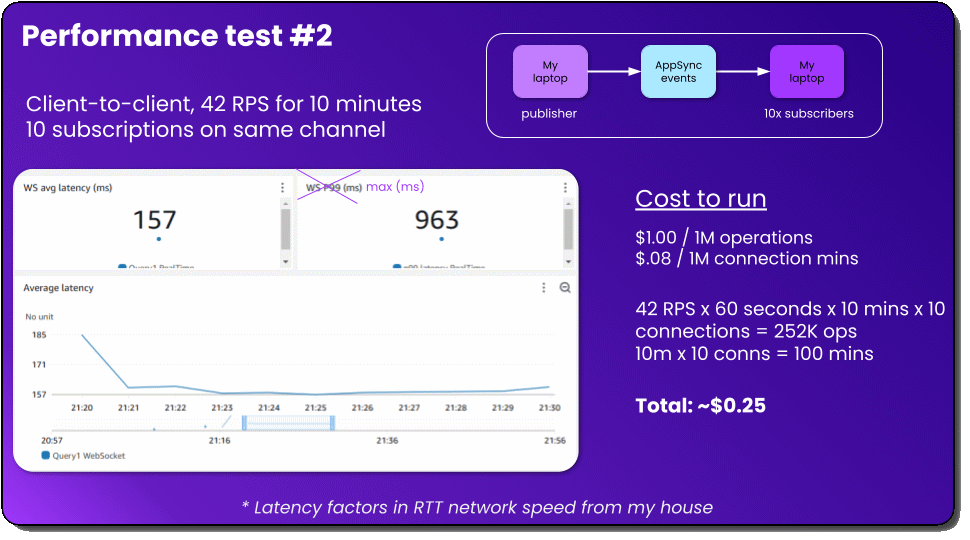
Client-side performance test
Now time for a realistic test from a use case perspective. I both published and subscribed to messages from my laptop (an end user machine) to simulate a chat room. I was publishing directly to the service via the HTTP publish method and calculating the round-trip time (RTT) to respond via my subscriptions. This RTT includes the network latency from my home internet, and mileage will vary based on where you are in the world.
Understandably, the average latency here is a little slower at 157ms because of the network latency at my house. The slowest call is 963ms, which is much faster than our server-side load test, but I also sent 126 million fewer messages, so the sample size was much smaller 😅 I wasn’t able to get the p99 for this one, I had done my metric calculations wrong initially and had help from the AppSync team for my big test, but not this one.
I noticed what seemed to be a little bit of a cold start on both tests, I don’t know enough about the internal architecture of the service to say why it behaves that way, but I’ll point out that the scaling mechanism they have is pretty darn fast.
Overall, I’d say I’m satisfied with the performance. It falls within our acceptable range for latency and seems to be pretty consistent. Does it blow me out of the water with single digit millisecond latency? No. But does it provide a choppy, jarring real-time experience for users? Also no.
Roadmap
At AWS re:Invent, a session was held talking about how it all works and what was coming in (hopefully) 2025. There are some cool things on their way, with many of them focusing on connectivity - the bread and butter of AWS.
I’m excited to see how these shape the usage patterns of the service. What I have to mention when looking at this though is that everything you add between “send” and “receive” will add to the end-to-end latency. And that’s not a slam on AppSync team, that’s a warning to builders adding a bunch of stuff in the way of message delivery.
What you really wanted
If I had AppSync events years ago when I first started getting into real-time communication I would have been elated. It does so much and the flexibility of it after they launch some roadmap items is going to bring a wealth of possibilities to do really whatever we want. But I feel like I still own too much of the responsibilities when I use it.
I don’t want to write code to scope down authorization. I don’t want to build some sort of mechanism to check if I’m receiving messages out of order or dropping messages in transit. I don’t want to build an API to fetch messages I might have missed during a blip in my connection. These are solved problems, all I want to do is publish and subscribe.
What you’re looking for is something that does all the hard things. Both types of auth, message buffering, delivery retry, connection management, routing, all the stuff that doesn’t directly solve your business problem. You probably already know the solution I’m partial to. I went from building everything myself to building… nothing, really. Just a couple of API calls. But I digress.
As we roll into 2025, we know that real-time communication shouldn’t be as hard as it is. You should be able to connect backend services together, browser sessions together, backend services to browser sessions, and everything in between. WebSockets is an implementation detail. You have many options when it comes to data transfer, each with their own specific use case.
Alright, rant over. Stop calling it WebSockets. Go for managed. Great job, AppSync team.
Allen is an AWS Serverless Hero passionate about educating others about the cloud, serverless, and APIs. He is the host of the Ready, Set, Cloud podcast and creator of this website. More about Allen.


 Share on:
Share on: